Description
WE NEED TO INTEGRATE WITH ONE OR MORE EMBEDDING/LLM SERVICES
I put together a prototype where no cut-n-paste is needed to demo the Vector capabilities in Couchbase onprem server. I will outline the behaviour via a series of steps and later attache a short video.
Adding this "real" functional capability took essential 12 hours on the weekend NOT to access the embedding servers or LLMs but rather to put it all together in our current UI to access a 55 line python proxy that supplies real embeddings and accesses real LLM at OpenAI.
STEPS TO SHOW UTILITY OF THIS PROPOSED CAPABILITY
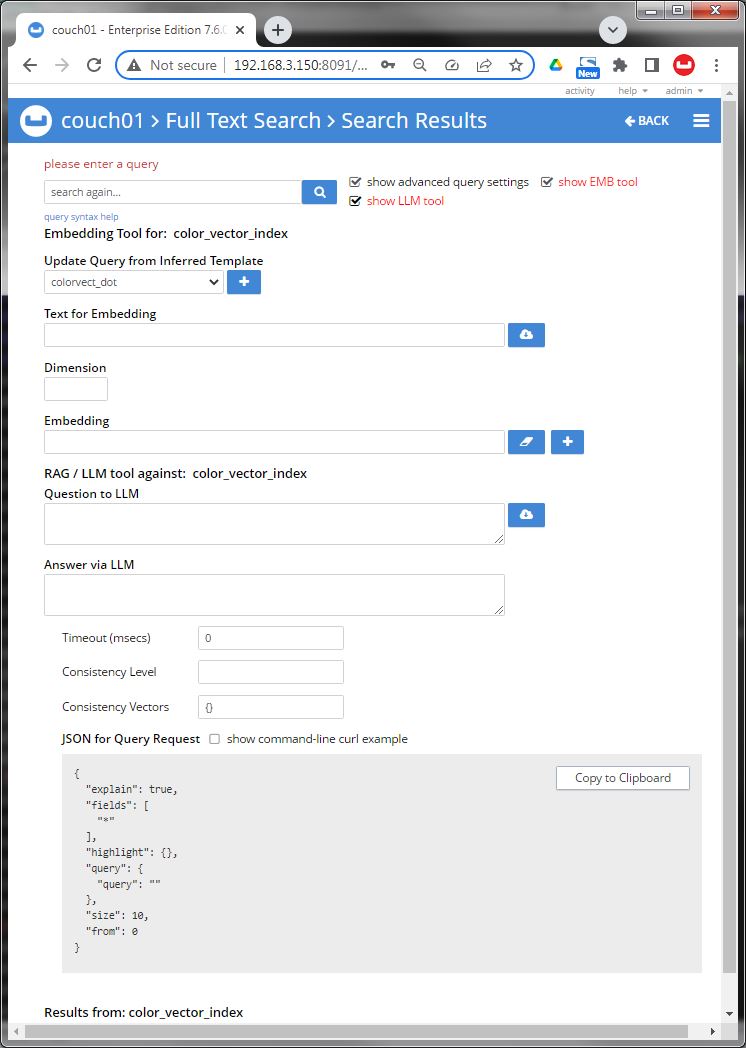
Image 00 shows a blank query for on prem with some "hacked in" plugins.
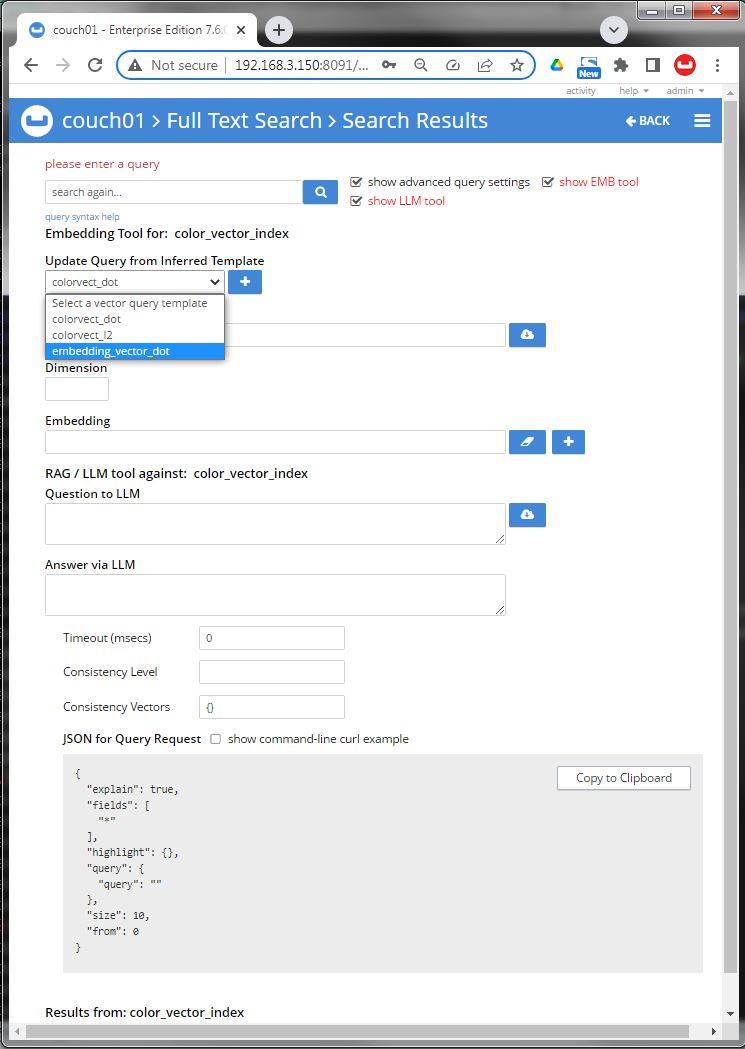
Image 01 shows selecting a query template based on indexed field (or type vector) where the template was made on the fly from the index we are querying. By selecting a template we get a working query but a nonsense vector.
Image 02 shows a template for a 1536 dimension vector. The query is now legal it will return something when run (provided that data exists and was indexed).
Image 03 shows an uncheck of "[ ] show advanced query settings" so we can see the query results, and hitting the magnifier to run the query. THE USER DID NOT HAVE TO TYPE ANY SYNTAX.
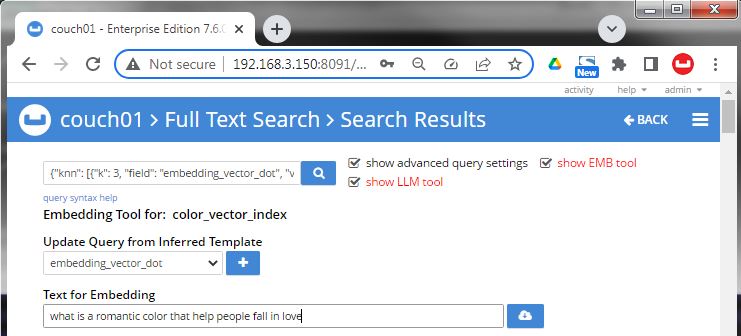
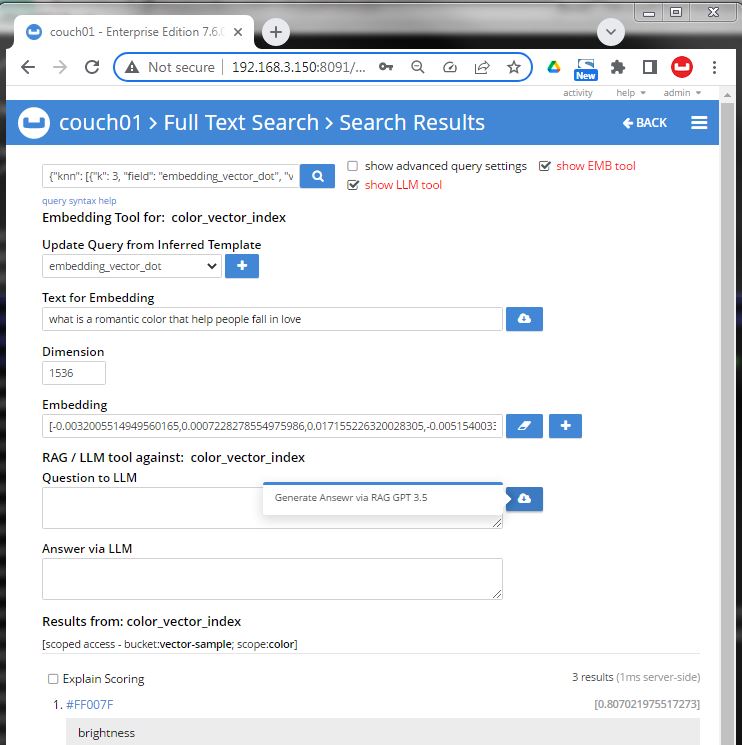
Image 04 type in a textual query under "Text for Embedding" this text should be relevant to the corpos that is vectorized in the couchbase database and also indexed under the specific index field. I chose "what is a romantic color that help people fall in love"
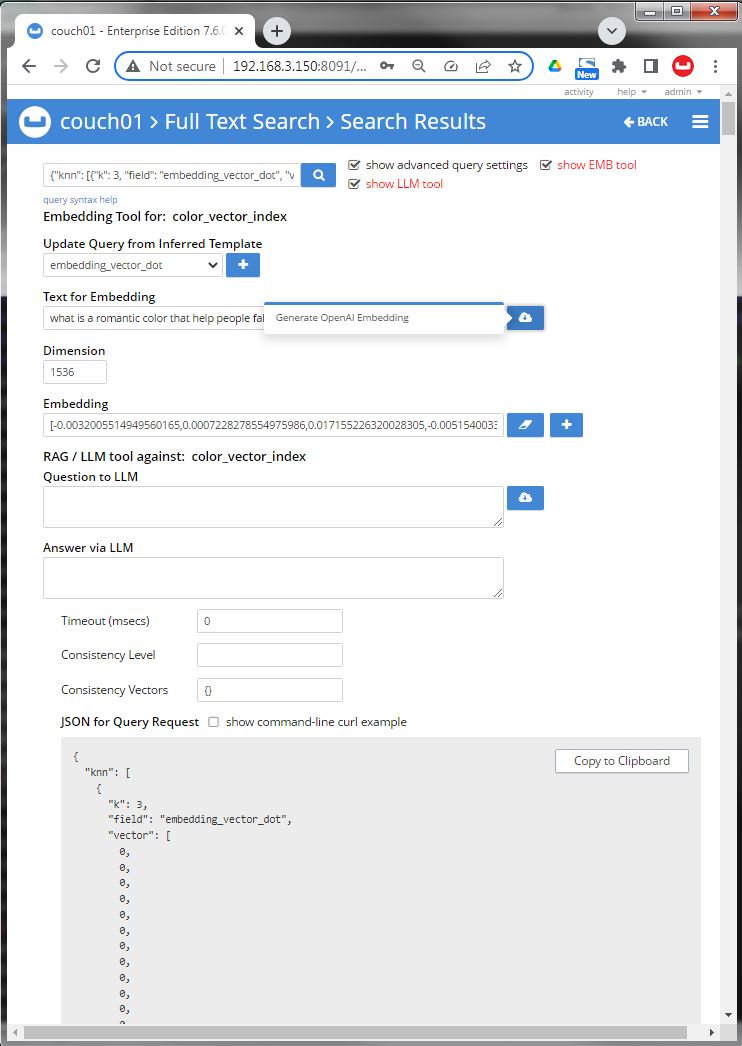
Image 05 recheck "[X] show advanced query settings"to hit the cloud button and the "hacked in" plugin for embedding contacts and fills in a Vector and shows the dimension (for fun).
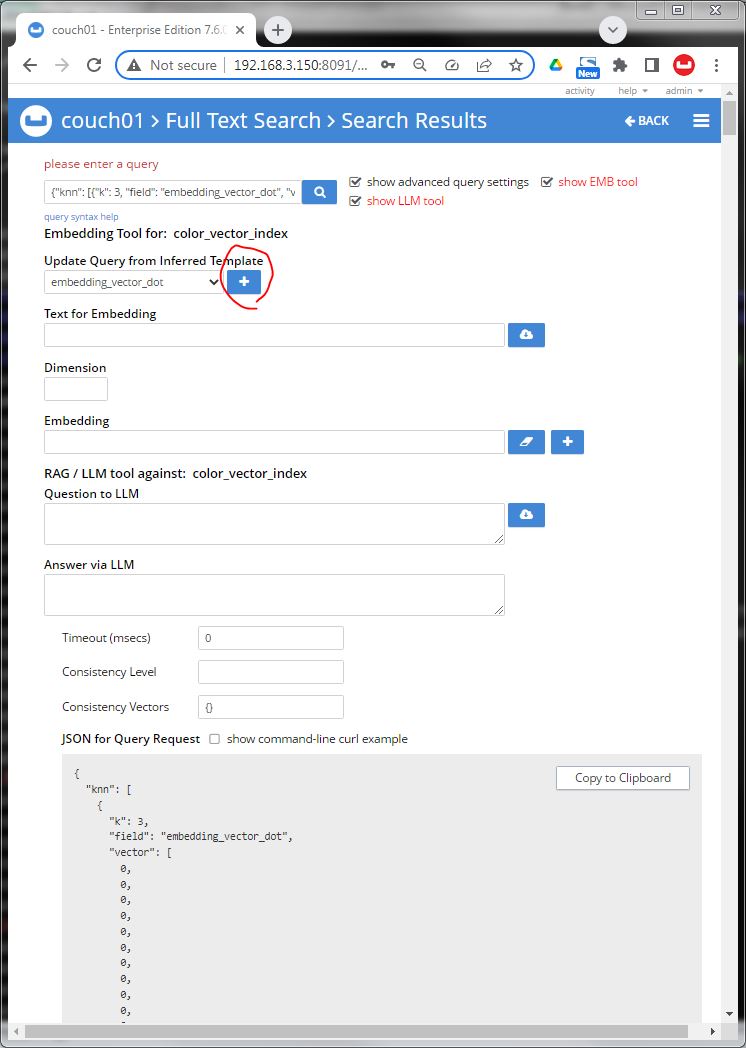
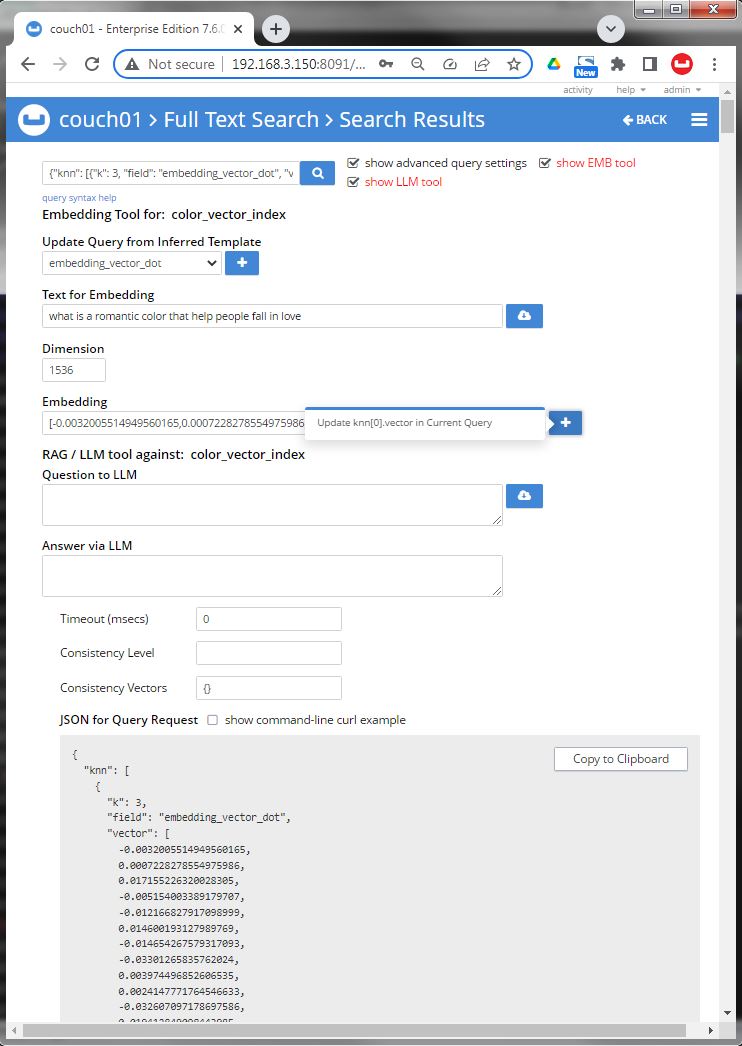
Image 06 now hit [ + ]next to the Embedding to replace the search vector in the JSON query.
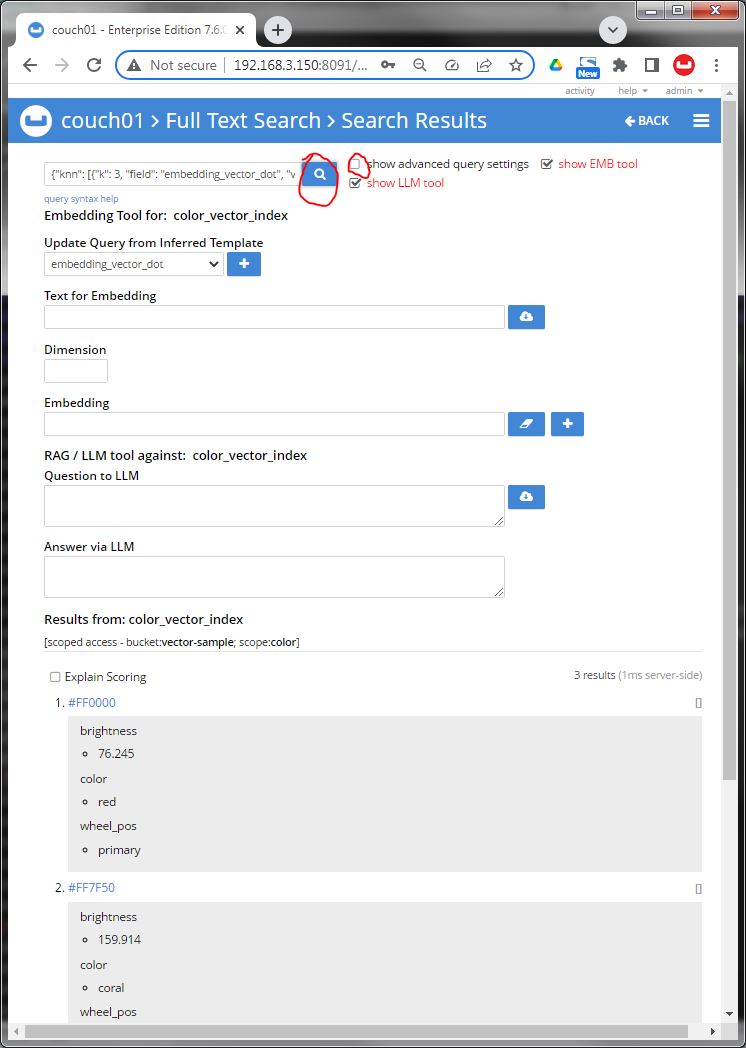
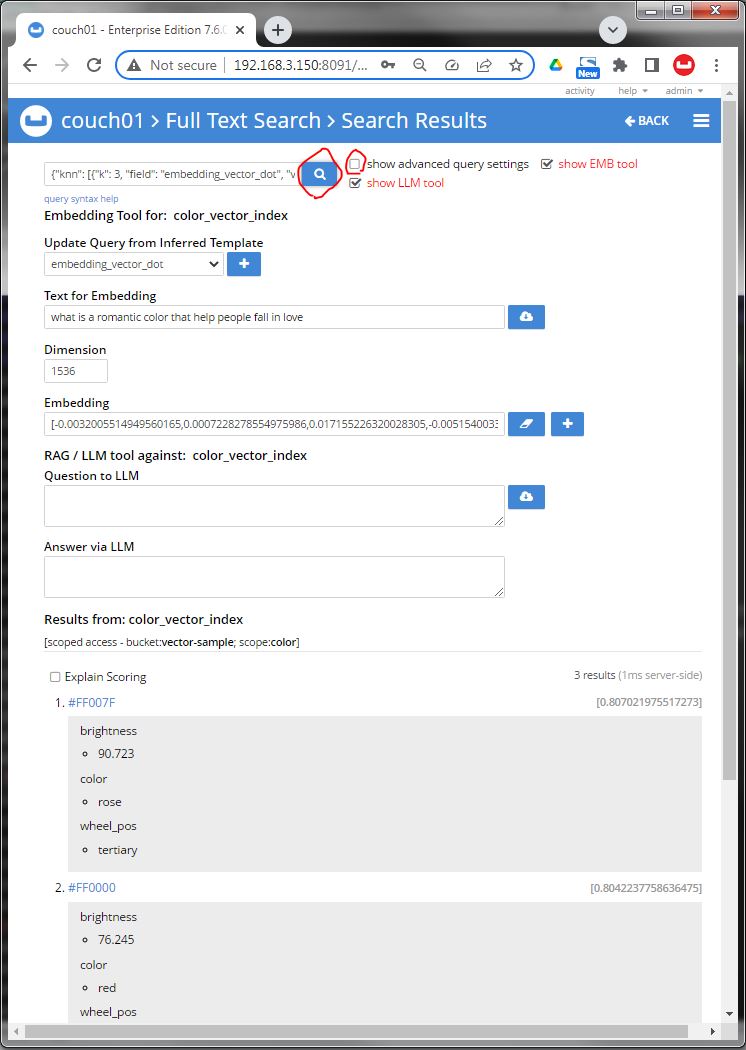
Image 07 again we uncheck "[ ] show advanced query settings" so we can see the query results, and hitting the magnifier to run the query. THE USER DID NOT HAVE TO TYPE ANY SYNTAX - only the question to apply against the corpus. We got three hits.
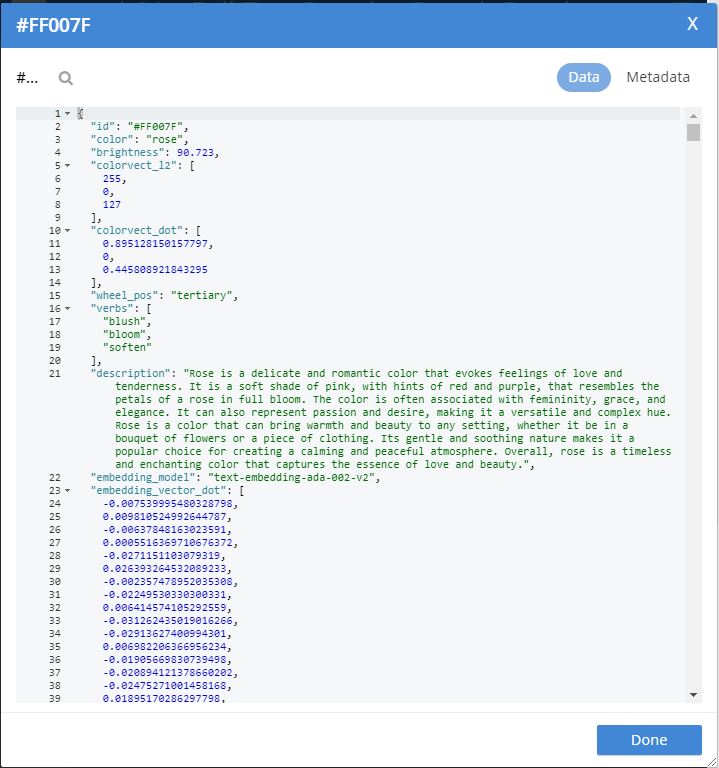
Image 08 verify lets look at doc #FF007F and yes it looks good the text associated with the color had a description that included ".... Rose is a delicate and romantic color that evokes feelings of love and tenderness ..." this matched the semantic search of the query text we made our embedding from back in Image 04
Image 09 Test the last part of retrieval augmented generation (RAG) via hitting the lower cloud button next to "Question to LLM"
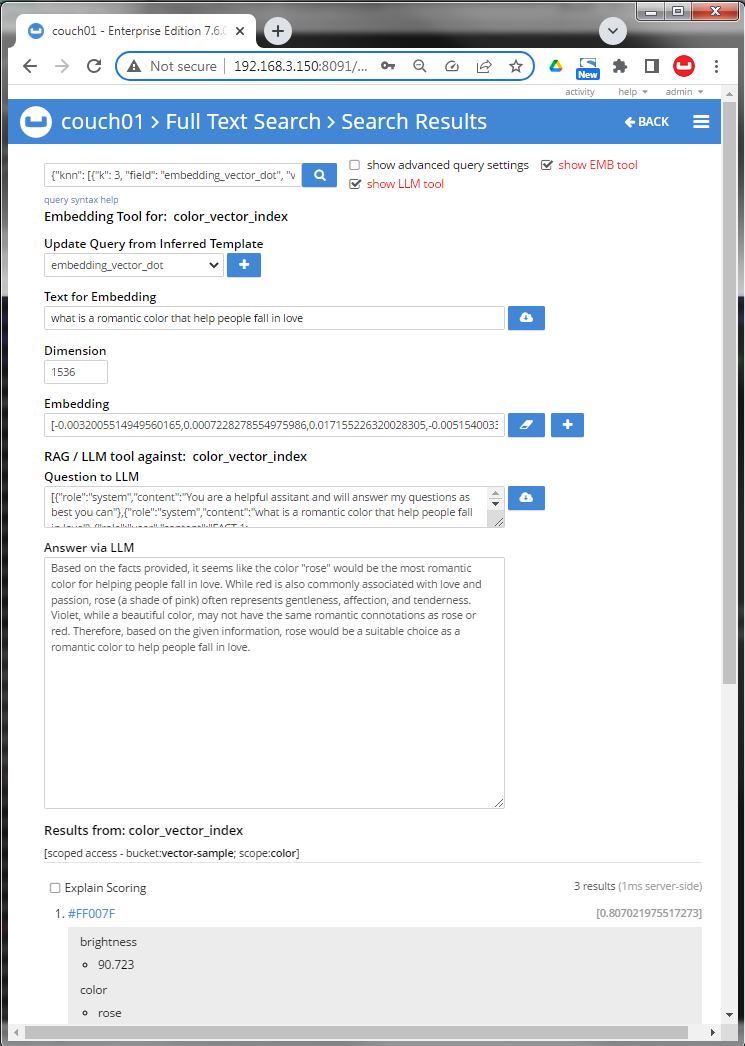
Image 10 mouse over the textarea under Question to LLM it will consist of all stored field form each of the three reported index hits - this is the retrieval context. Along with the original question form Image 04 and some directions to the LLM
Image 11 final LLM answer.
CONCLUSION
The use of an embedding server and an LLM while quite simple code wise - below is an example of making an embedding call in python:
import os
|
import openai
|
openai_api_key = os.getenv("OPENAI_API_KEY")
|
text = "What is the meaning of the color that absorbs all light and conceals objects in darkness?"
|
response = openai.Embedding.create( input=[text], model="text-embedding-ada-002" )
|
print(response.data[0].embedding)
|
The call to a large language model LLM is equally simple
import os
|
import sys
|
import openai
|
openai.api_key = os.getenv("OPENAI_API_KEY")
|
user_input = "What color seems to minimize or hide all other colors?"
|
messages = [{"role": "user", "content": user_input}]
|
response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=messages )
|
print(response.choices[0]["message"]["content"])
|
The key is integrating these calls into our UIs to allow Couchbase to demonstrate the complex steps of RAG end to end within the UI to demonstrate the full power of our vector store.
CLOSING THOUGHTS
I used a proxy but we could also use Eventing or a UDF to do the same or even allow the user/customer to bring their own key and provide the needed service.
If we provide the needed service we need to store the users "bearer" in a safe encrypted fashion for example OpenAI might have a key like the following (bash sh example not this key will not work)
OPENAI_API_KEY=sk-39c8I25P2MHP5wfuJMKQT3BlwkFJ64IywBSGRhvHVlGI3Miv
|
export OPENAI_API_KEY
|
In Eventing we encrypt keys and passwords in metakv not sure if this is best practice.
We could even use our own Couchbase key and allow at most 6 embedding calls and/or LLM calls per minute. By this I mean just use the companies OPENAI_API_KEY and use Capella IQ but it would be critical to rate limit each authenticated user to say 5 calls per minute so as not to provide a free embedding/LLM backdoor.This would let our UI just work and make ease of kicking the tires better than the experience our customers give as we could do everything in our UI by this I mean demoing end-2-end retrieval augmented generation (RAG).