Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
7.2.2
-
Untriaged
-
0
-
Unknown
Description
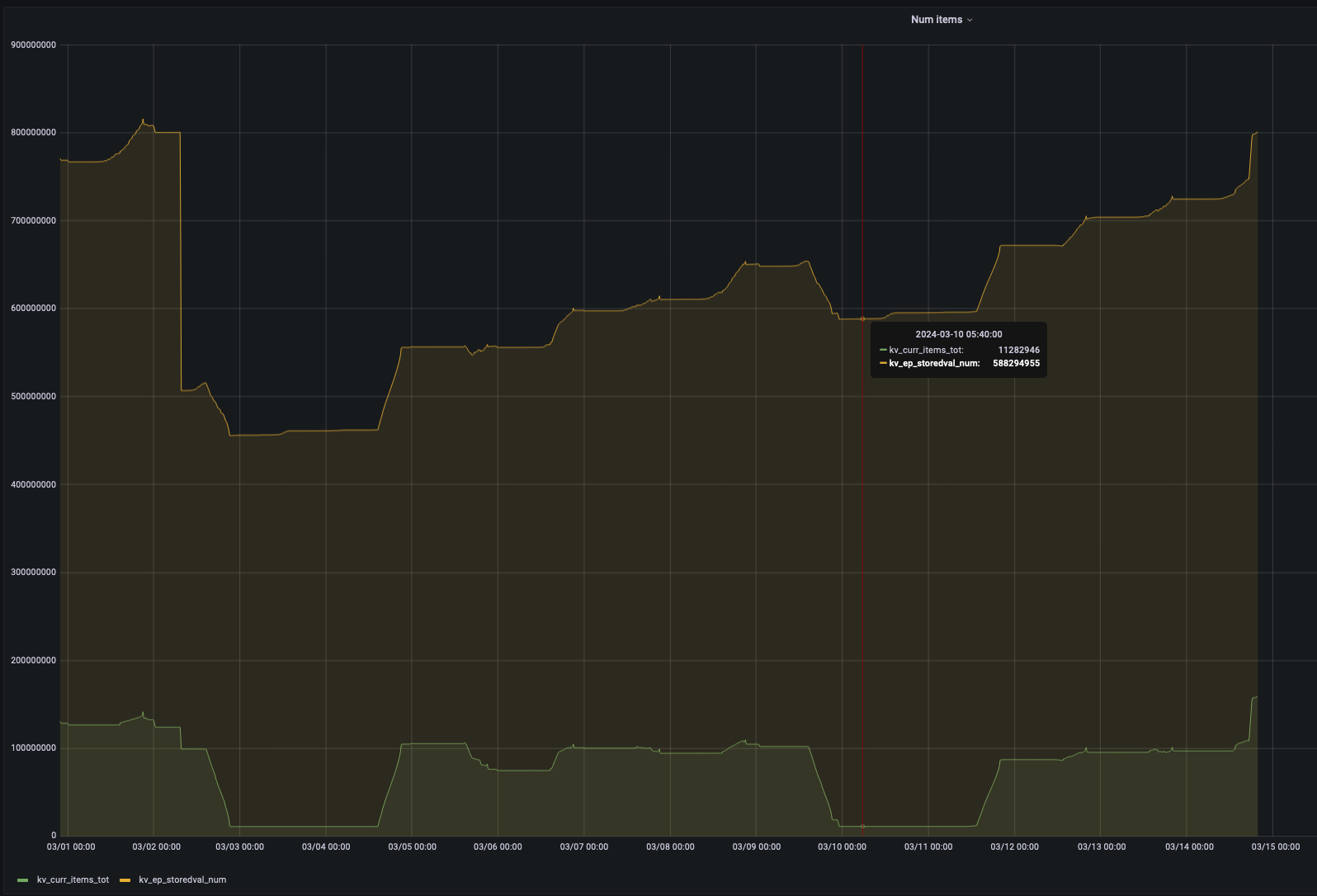
From a real cluster following was first observed whilst investigating a performance issue. The bucket is 100% resident, but noted that the kv_ep_storedval_num is much higher than kv_curr_items_tot, what are all of these extra StoredValues?
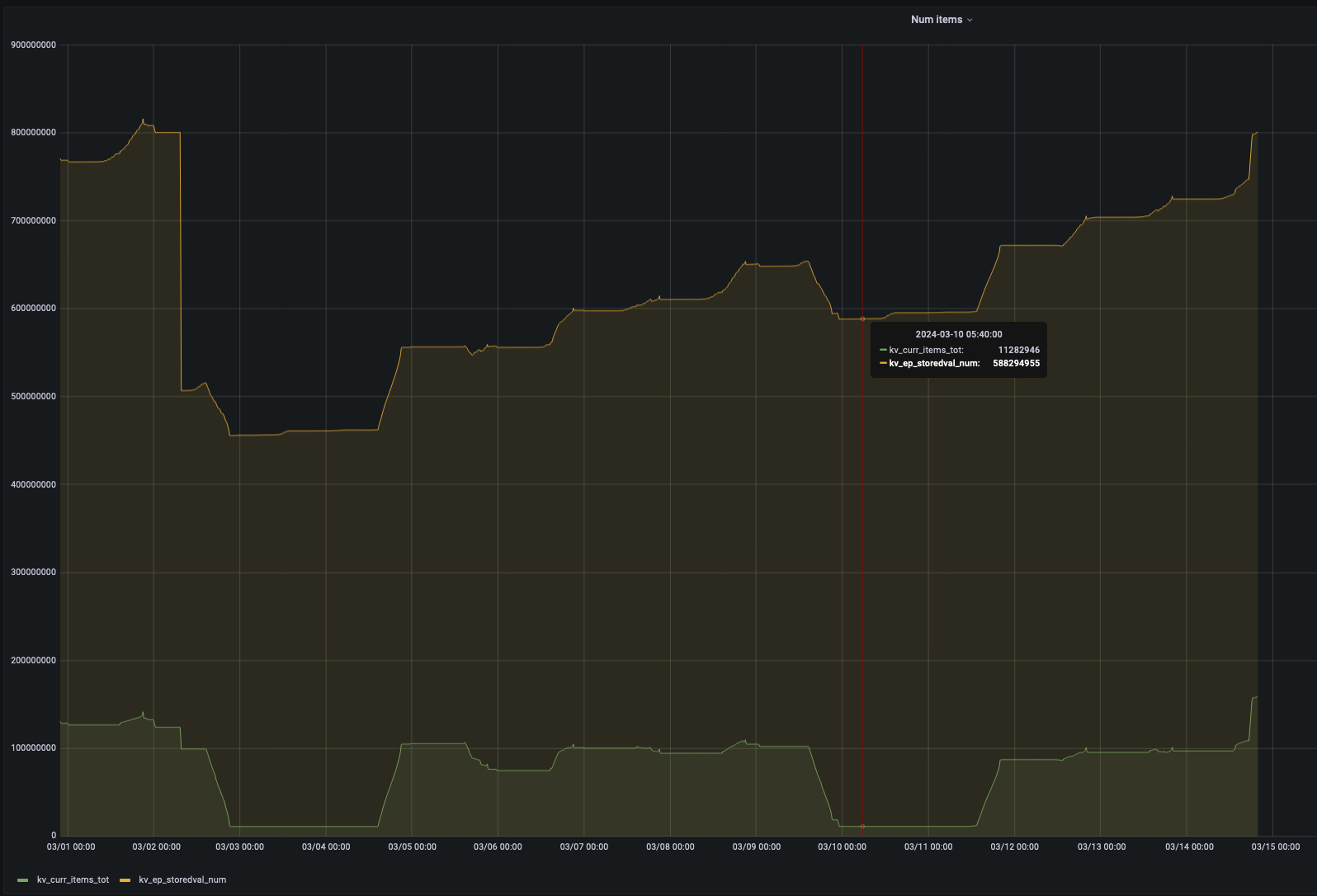
Later noted in stats.log vbucket-details that the hash-table stats explain this difference, ht_num_temp_items accounts for the huge number of temporaries.
vb_0:ht_num_deleted_items: 11318
|
vb_0:ht_num_in_memory_items: 396839
|
vb_0:ht_num_items: 396839 <-----
|
vb_0:ht_num_temp_items: 7448340 <----
|
vb_0:ht_size: 393209 <-!!!!!
|
This causes some further problems.
- We clearly use more memory than needed.
- The hash-table is sized based on ht_num_items, yet the hash-table also stores the temporaries.
- This results in long hash-table chains, in the above case chains of ~20, meaning a hash-table lookup in the worst case is now 20 times worse than the optimal case of 1 item per hash-table bucket (20x latency increase in worst case).
- Secondly when the hash-table does resize, these temporaries must also be moved, hash-table resizing is much costlier than needed - again increasing latencies.
- Finally, any hash-table visit task must also visit these temporaries - again increasing latencies (e.g. periodic expiry pager is having to look at 600m items instead of 80m).
The cause is suspected to be related to expiry driven from compaction and relates to a detail of magma. Magma compaction can see "old" versions of a key, meaning we may see multiple callbacks per key.
My theory is along these lines.
- The expiry pager expires a bunch of items - generating deletes which get flushed to magma. E.g. delete(k1, seq=2)
- or the workload deletes data
- or even compaction based expiry itself (magma iirc compacts in chunks/tables, so may expire k1 from a table and still have k1 elsewhere)
- The point is that the hash-table no longer has k1, and it is alive somewhere in magma (ready to expire)
- magma soon after runs compaction and sees k1 @ seq=1 (the old version) and expires this key.
- The MagmaKVStore integration requires that we don't delete any new version of this key, e.g. their could be a new k1 @ seq 3.
- First this block is reached as k1 is not in the hash-table https://src.couchbase.org/source/xref/7.2.2/kv_engine/engines/ep/src/vbucket.cc?r=c88c04aa#2587-2616
- Next the temporary is added here line 855 https://src.couchbase.org/source/xref/7.2.2/kv_engine/engines/ep/src/ep_vb.cc?r=e69faeb8#851-880
- Later the bg-fetch completes with key-not-found and we reach the completion function here, status is "not-found" so early return https://src.couchbase.org/source/xref/7.2.2/kv_engine/engines/ep/src/ep_vb.cc?r=e69faeb8&fi=completeCompactionExpiryBgFetch#260
- The temporary added earlier is left in the hash-table - note how we have incremented stats.bg_fetched_compaction
- The MagmaKVStore integration requires that we don't delete any new version of this key, e.g. their could be a new k1 @ seq 3.
I believe we can see this pattern in the cbcollect data as follows.
The following three charts are plotting the deltas (so we can better see how all of these data points change together) of:
- Top chart - kv_curr_temp_items - we see about at 13:29 a 100k increase in temporaries
- Middle chart - compaction bg_fetches completing (the stat I highlighted in completeCompactionExpiryBgFetch)
- Lower chart - both kv_curr_temp_items and kv_curr_items_tot - this chart allows us to see when temporaries increase but curr_items didn't, and over the cbcollect we could see various points where we clearly accumulate temporaries.
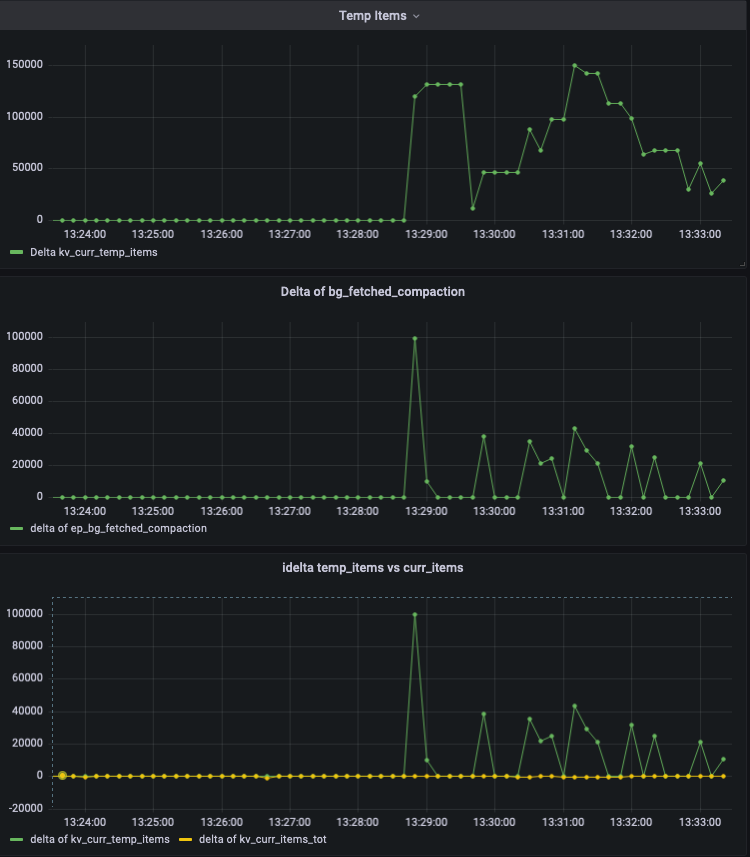
Less clear is when the initial expiry or delete occurs, the operation which removes k1 from the hash-table leading to the bg-fetch, but we do observe a mix of pager based expiry and compaction expiry minutes before the increase in temporaries.
Next is to reproduce and fix.
Attachments
Issue Links
- mentioned in
-
Page Loading...