Details
-
Bug
-
Resolution: Won't Fix
-
 Critical
Critical
-
7.6.2
-
7.6.2-3714
-
Untriaged
-
-
0
-
Unknown
Description
Steps to reproduce:
- Create a cluster- 5 FTS nodes - 32GB ram and 16vCPU per node
- Load ~60M vector data
- Create 4 FTS indexes, 80 partition per index ( 1 index partition per vCPU )
- Keep constantly inserting vector data ( dcp ingestion remains active for FTS)
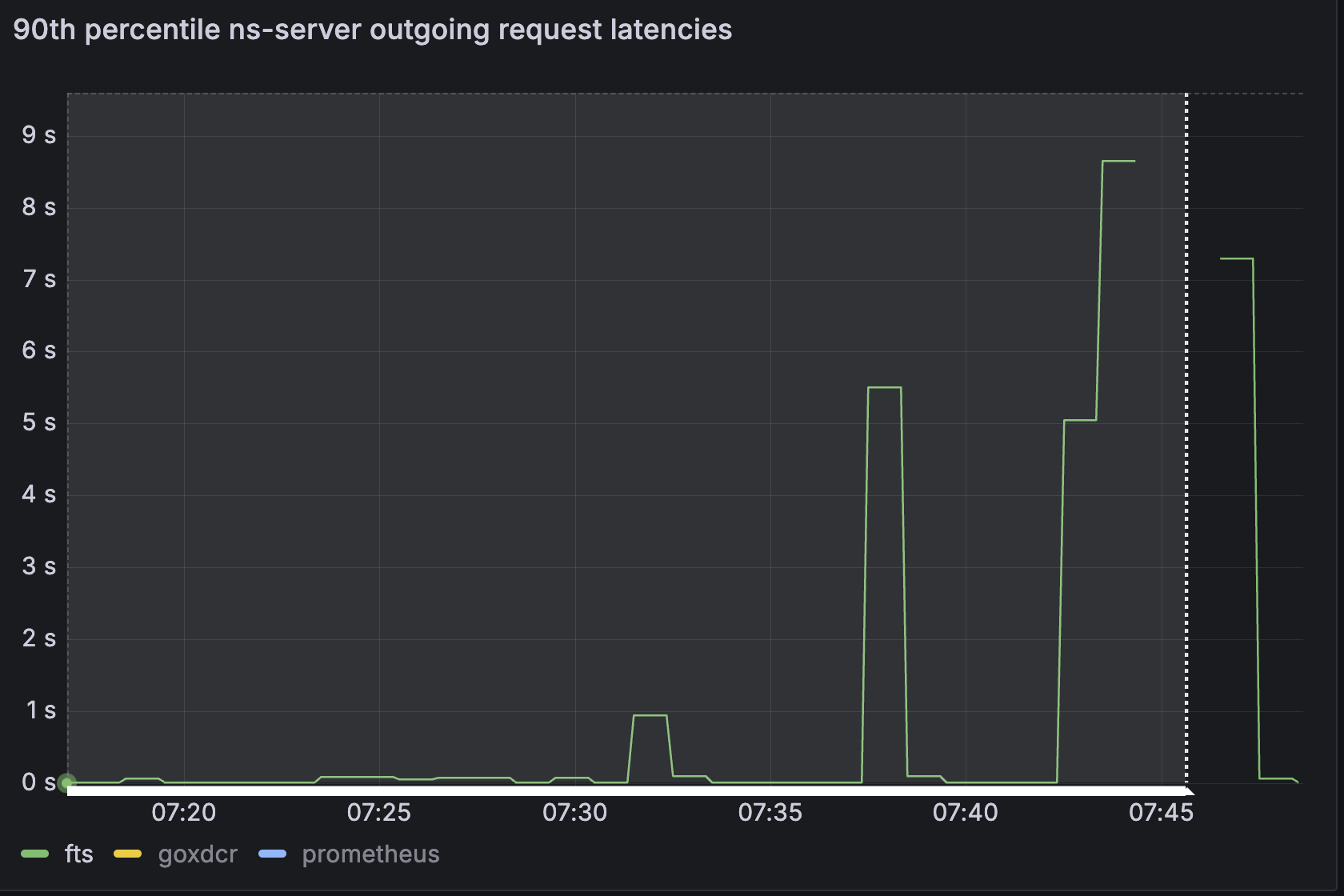
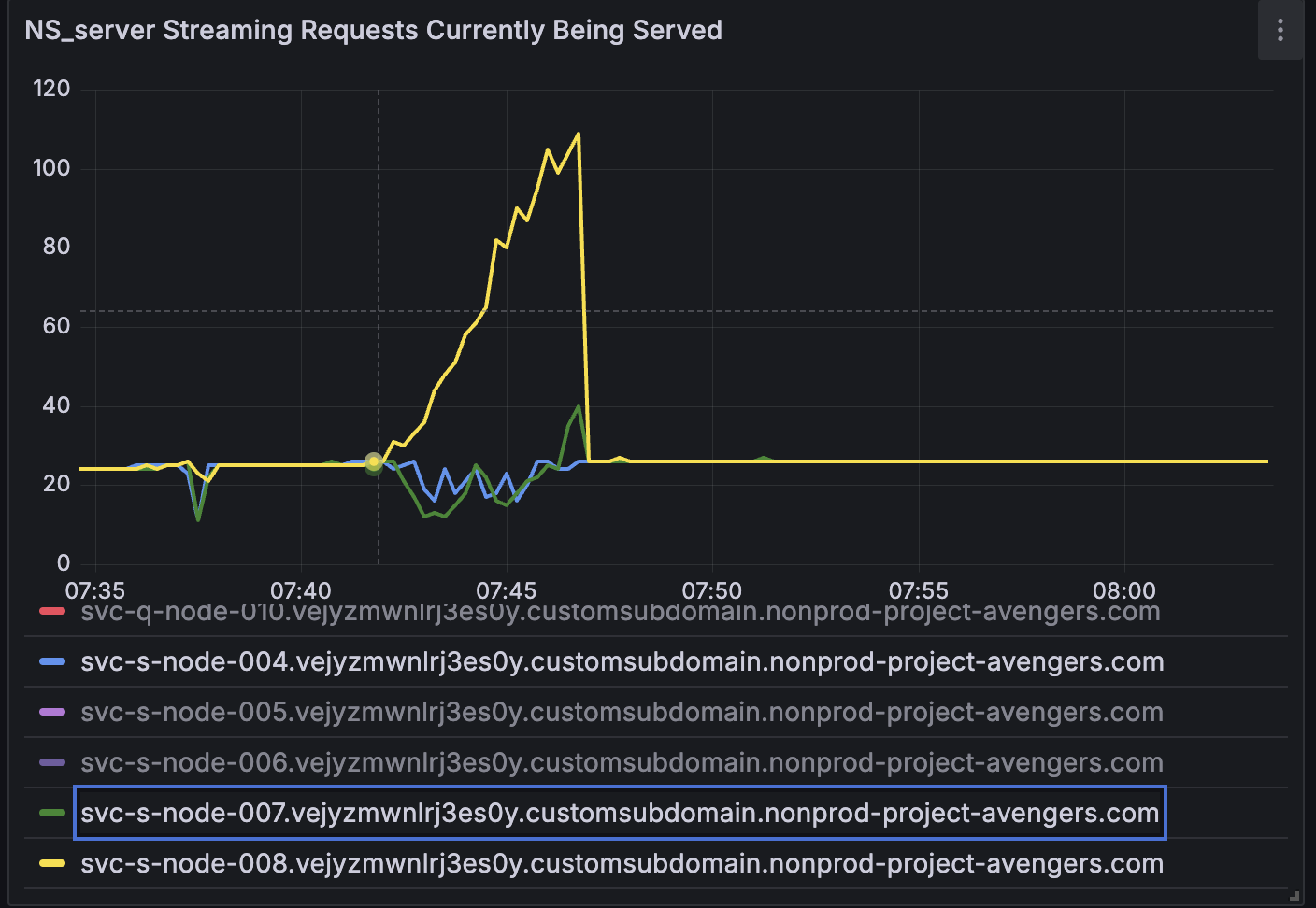
Rebalance out 1 node from the cluster. Rebalance fails with ;
7:45:37 AM 15 Jun, 2024 |
Rebalance exited with reason {service_rebalance_failed,fts,
|
{worker_died,
|
{'EXIT',<0.7340.24>, |
{task_failed,rebalance,
|
{service_error,
|
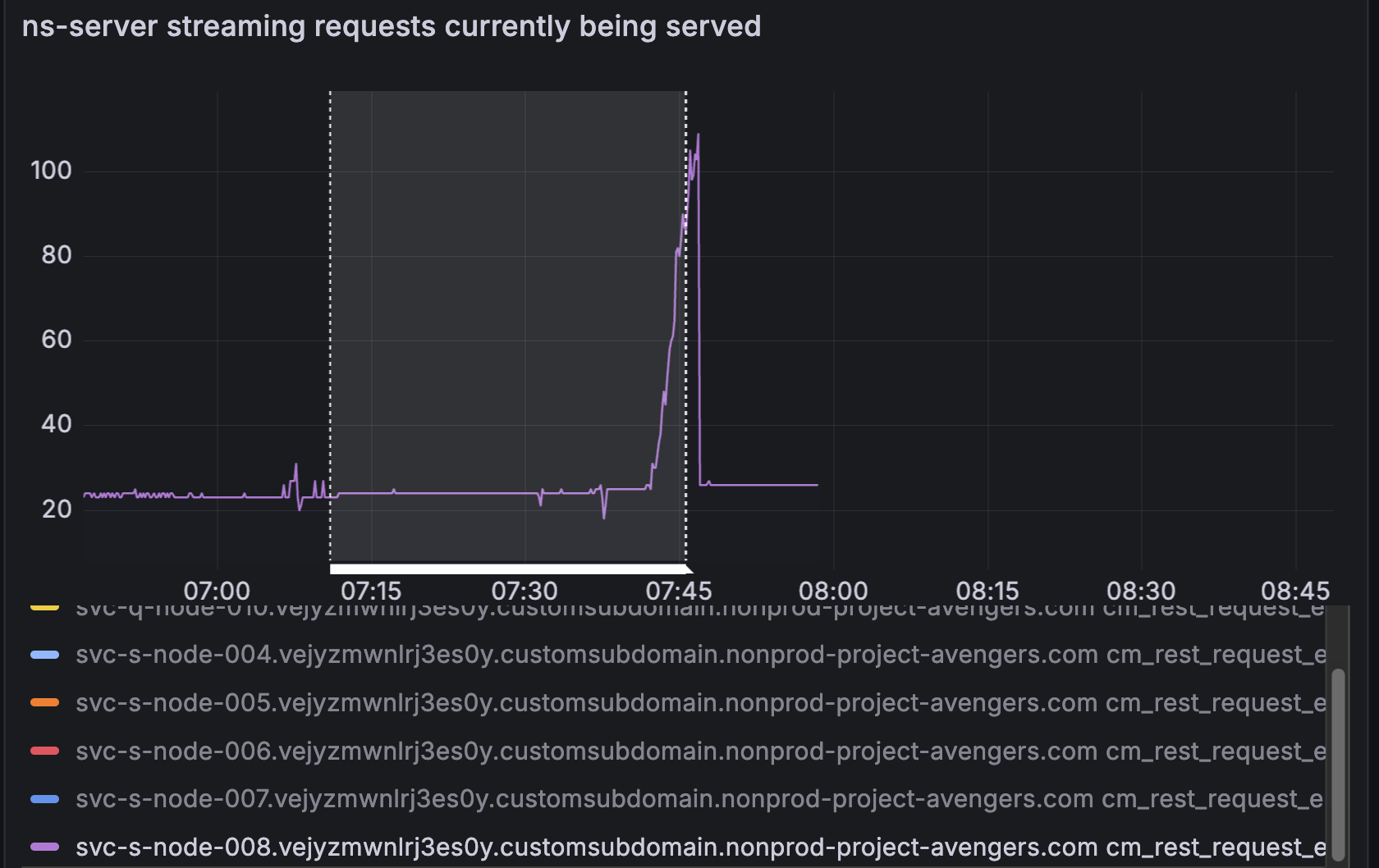
<<"nodes: sample res.StatusCode not 200, res: &http.Response{Status:\"503 Service Unavailable\", StatusCode:503, Proto:\"HTTP/1.1\", ProtoMajor:1, ProtoMinor:1, Header:http.Header{\"Content-Length\":[]string{\"50\"}, \"Content-Type\":[]string{\"text/plain; charset=utf-8\"}, \"Date\":[]string{\"Sat, 15 Jun 2024 07:45:36 GMT\"}}, Body:(*http.bodyEOFSignal)(0xc2020bd740), ContentLength:50, TransferEncoding:[]string(nil), Close:false, Uncompressed:false, Trailer:http.Header(nil), Request:(*http.Request)(0xc0e5285b00), TLS:(*tls.ConnectionState)(0xc0111d6840)}, urlUUID: monitor.UrlUUID{Url:\"https://svc-s-node-008.vejyzmwnlrj3es0y.customsubdomain.nonprod-project-avengers.com:18094\", UUID:\"2c26104010bd76d7a003ae9aa05c34a6\"}, kind: /api/stats?partitions=true, err: <nil>">>}}}}}. |
Rebalance Operation Id = 6d0c2df944dcaac77d21eb72c21450ff
|
es0y.customsubdomain.nonprod-project-avengers.com
|
ns_1@svc-q-node-009.vejyzmwnlrj3es0y.customsubdomain.nonprod-project-avengers.com |
Stop the ingestion and let the cluster be idle. Retrigger the rebalance, Rebalance succeeds.
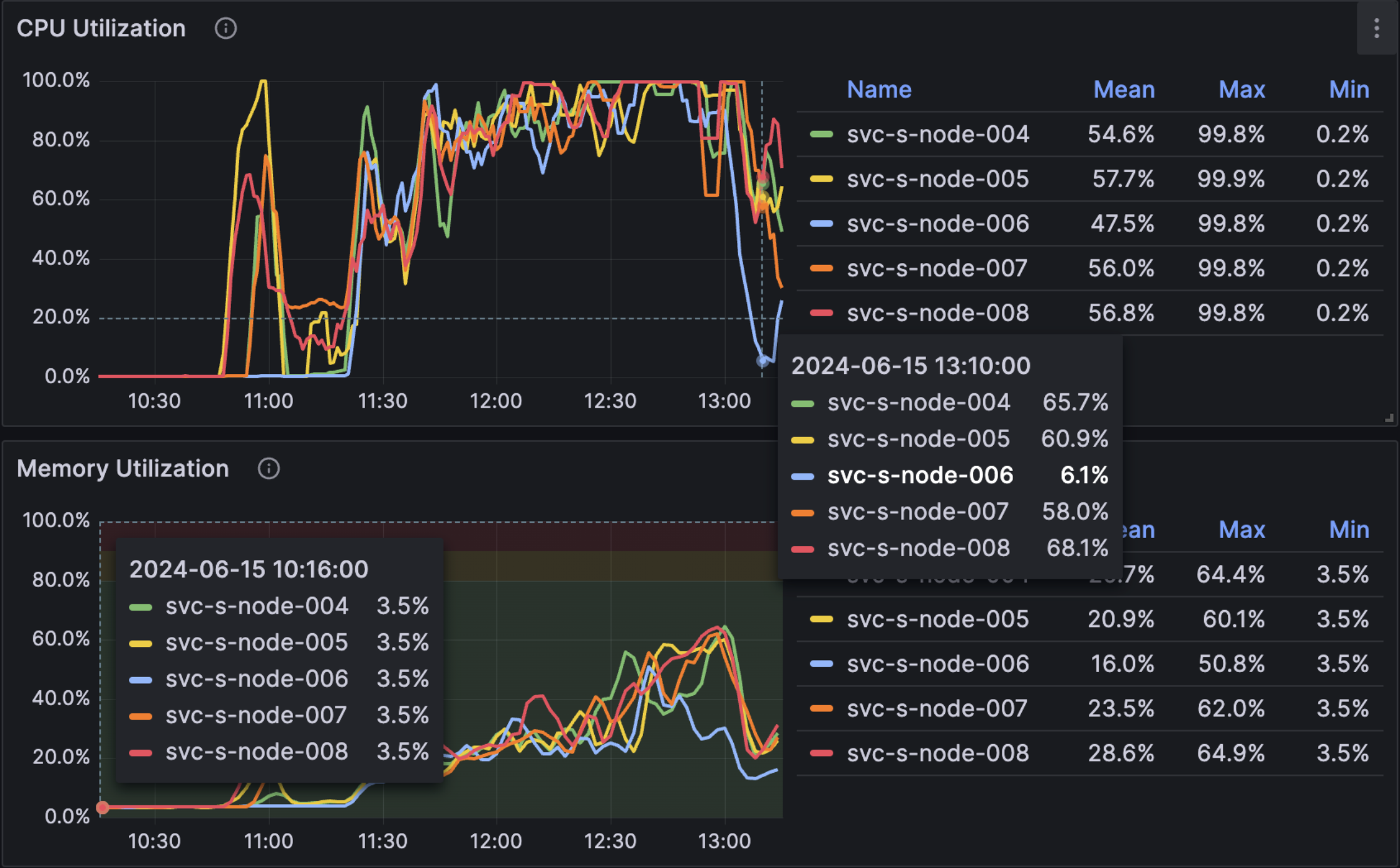
During rebalance both CPU and Memory were normal (60% cpu usage and 40% memory usage)
Attachments
Issue Links
- relates to
-
-
- Open
-