Details
-
Bug
-
Resolution: Not a Bug
-
 Critical
Critical
-
Cypher
-
8.0.0-1711
-
Untriaged
-
0
-
Unknown
Description
Setup cluster with 1 node and loaded siftsmall dataset.
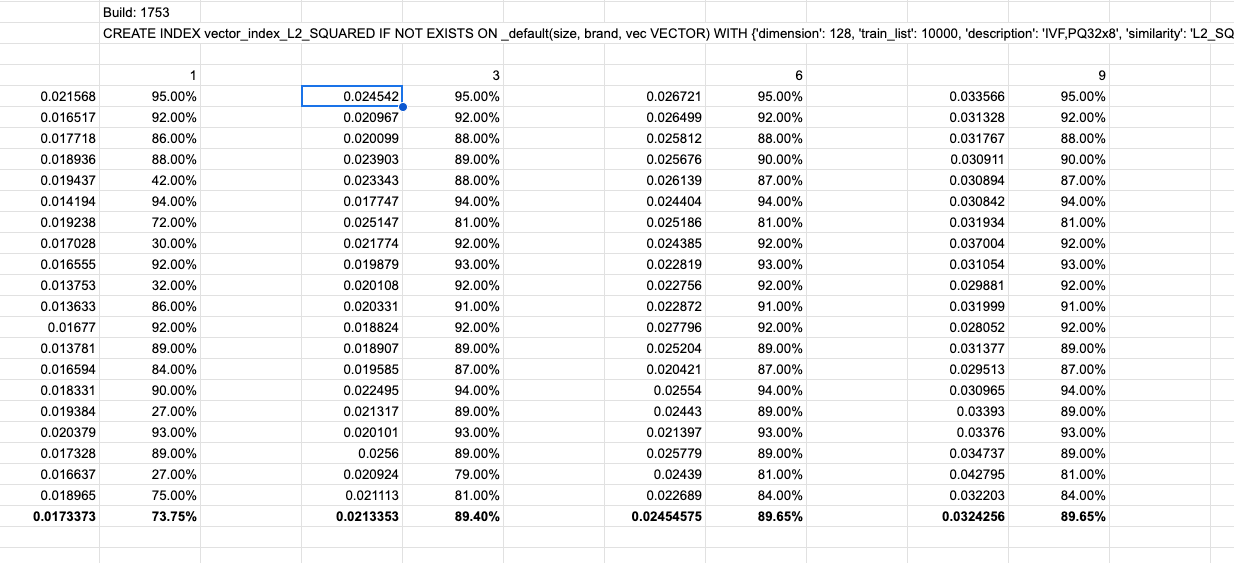
Create index:
CREATE INDEX vector_index_L2_SQUARED IF NOT EXISTS ON _default(size, brand, vec VECTOR) WITH {'dimension': 128, 'train_list': 10000, 'description': 'IVF,PQ8x8', 'similarity': 'L2_SQUARED', 'scan_nprobes': 3} |
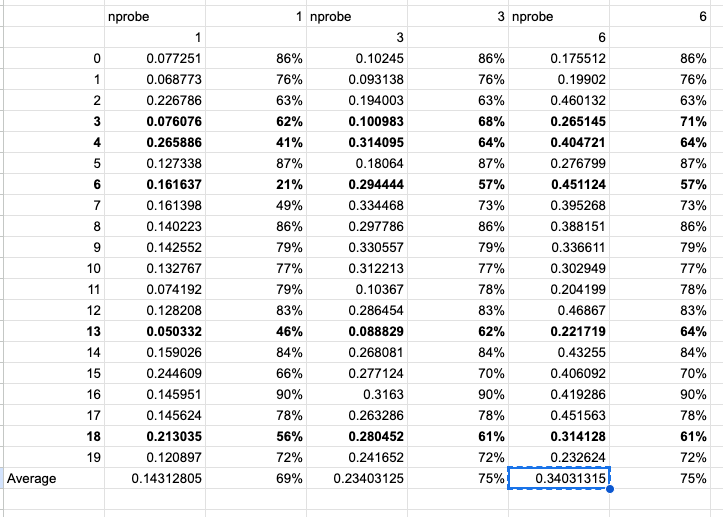
and run 10 queries but getting less than 1% recall. Note that recall is caluclated based on the expected ground truth for given vector query from sift
Running 1 threads X 10 queries |
|
|
|
|
Thread 0: Running query#0 with vector [44.0, 11.0, 0.0, 0.0, 6.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.023998 |
Recall rate: 0.0% |
Thread 0: Running query#1 with vector [38.0, 17.0, 6.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.032215 |
Recall rate: 1.0% |
Thread 0: Running query#2 with vector [0.0, 2.0, 2.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.022537 |
Recall rate: 0.0% |
Thread 0: Running query#3 with vector [38.0, 26.0, 0.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.032465 |
Recall rate: 0.0% |
Thread 0: Running query#4 with vector [36.0, 12.0, 0.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.032238 |
Recall rate: 1.0% |
Thread 0: Running query#5 with vector [148.0, 1.0, 0.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.034496 |
Recall rate: 0.0% |
Thread 0: Running query#6 with vector [115.0, 13.0, 0.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.028614 |
Recall rate: 0.0% |
Thread 0: Running query#7 with vector [3.0, 0.0, 0.0, 0.0, 1.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.030435 |
Recall rate: 1.0% |
Thread 0: Running query#8 with vector [82.0, 24.0, 0.0, 3.0, 2.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.017351 |
Recall rate: 0.0% |
Thread 0: Running query#9 with vector [3.0, 0.0, 0.0, 0.0, 0.0] ... |
Query: SELECT RAW id FROM _default WHERE size IN $size AND brand IN $brand ORDER BY ANN(vec, $qvec, "L2_SQUARED") ASC LIMIT 100 |
Execution time: 0:00:00.031369 |
Recall rate: 0.0% |
|
|
|
|
Ran # 10 (1x10) queries in 0.8 seconds |
Query per seconds: 12.54 |
with KNN and i can get 100% recall rate. Let me know if you need more details or state of index scan at this time.
Here is script i use to run test above: https://github.com/couchbase/testrunner/blob/master/scripts/vector_thread.py you would need to change based on your cluster and also change the query to use ANN (right now it uses KNN)
Attachments
| For Gerrit Dashboard: MB-62779 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 212964,2 | MB-62779: Send elements in ascending order from heap | unstable | indexing | Status: MERGED | +2 | +1 |