Details
-
Task
-
Resolution: Unresolved
-
 Major
Major
-
None
-
None
-
0
Description
A TreeSnapshot's memory is computed as:
size_t TreeSnapshot::MemUsed() {
|
auto memUsed =
|
sizeof(TreeSnapshot) + levelData.capacity() * sizeof(LevelData);
|
for (const auto& level : levelData) {
|
memUsed += level->tables.capacity() * sizeof(std::shared_ptr<SSTable>);
|
}
|
return memUsed;
|
}
|
We should be able to decide how many checkpoints we should have based on available memory quota as we know how much one checkpoint will take. We can assume the worst case 20 files per level.
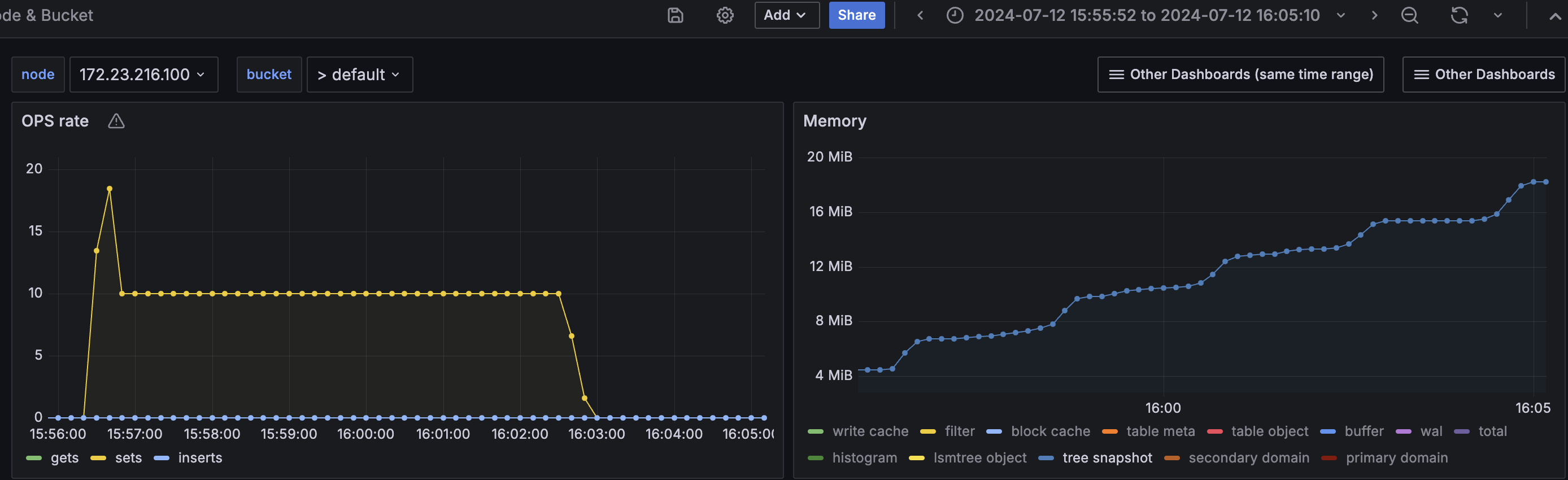
On a 100MB quota test, the target was to load 20k (active+replica) items. But the tree snapshot mem used went upto 18MB as the data loading went on, after a point it led to permanent tmp_oom due to kv's mutation mem threshold. The test couldn't complete.
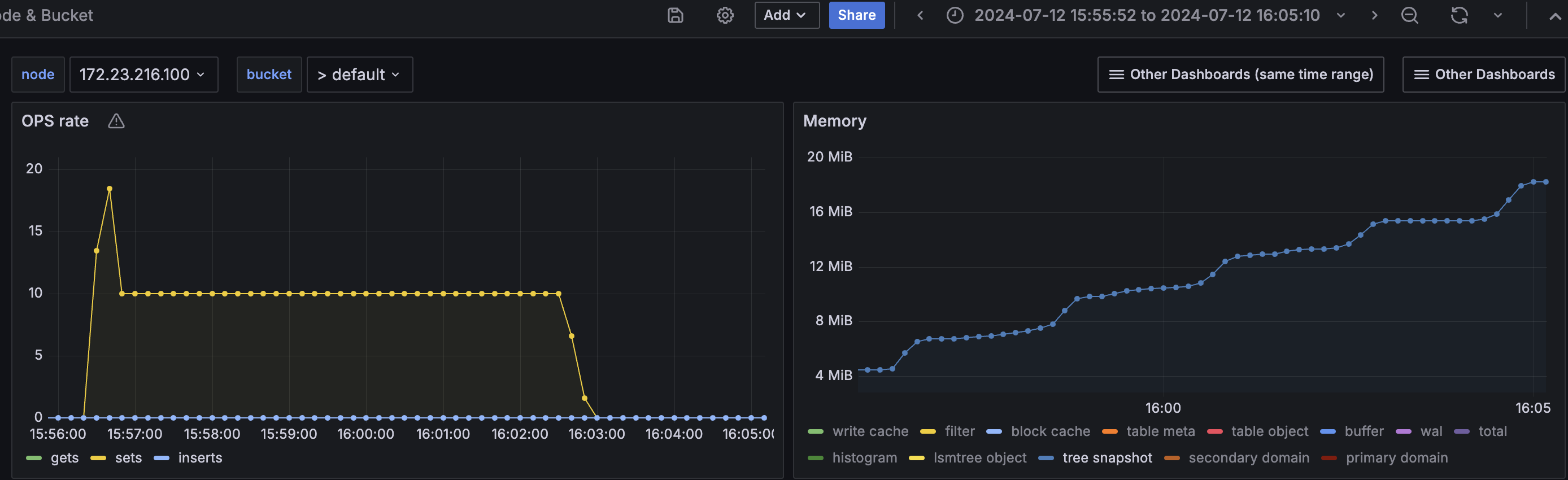
Setting number of checkpoints to 0 for the same tests, kept the tree snapshot mem used a constant at 6MB and as it didn't grow at all, the data loading could complete and the QE test passed.
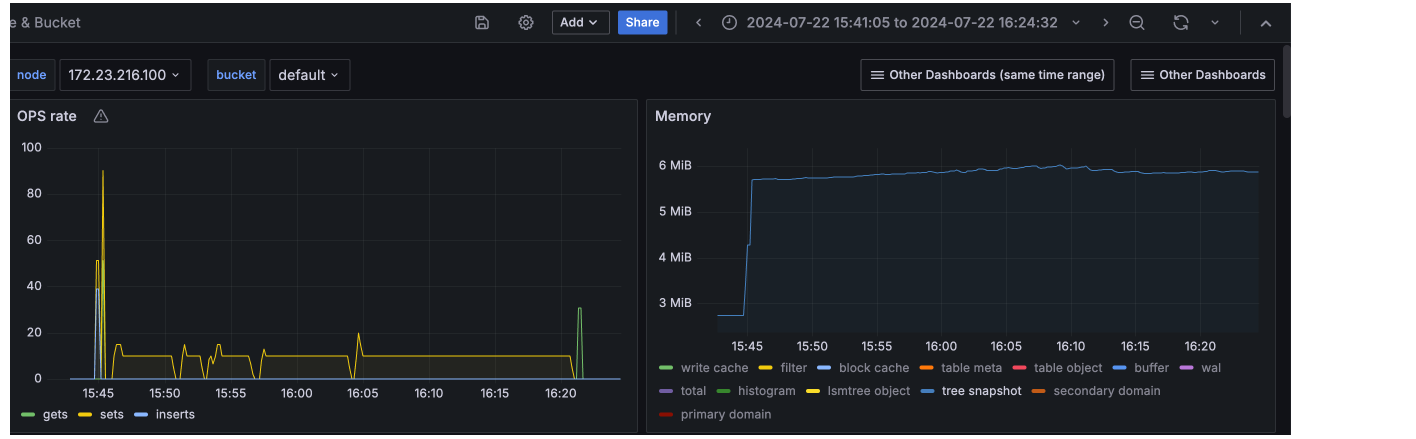
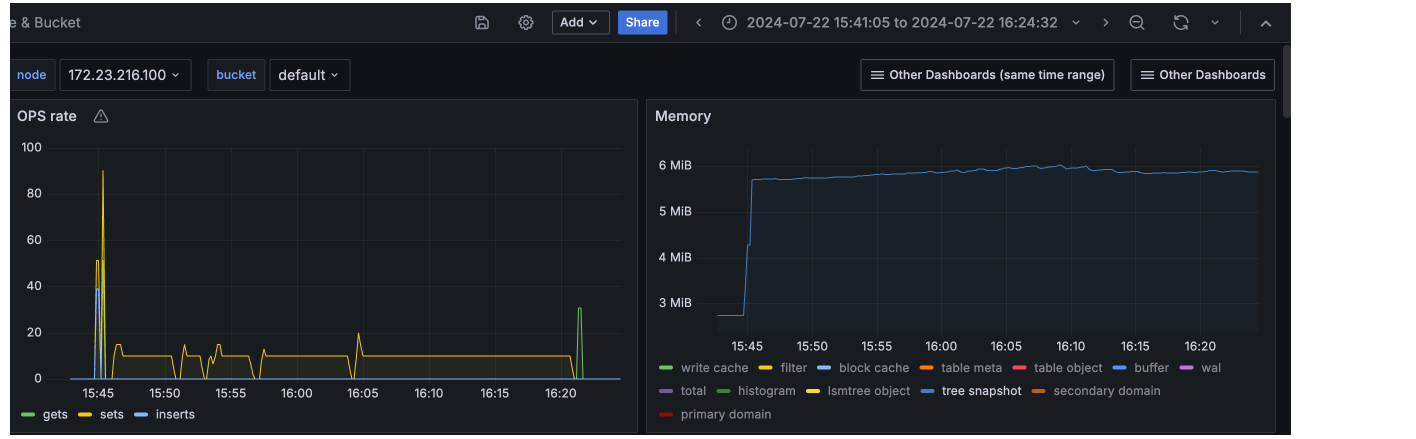
With this change, QE also tried loading 1M items. test didn't complete as it look long due to low ops rate , but even after loading 250k items, we can see Magma's mem_used is constant. None of the components now grow with the scale of the data.

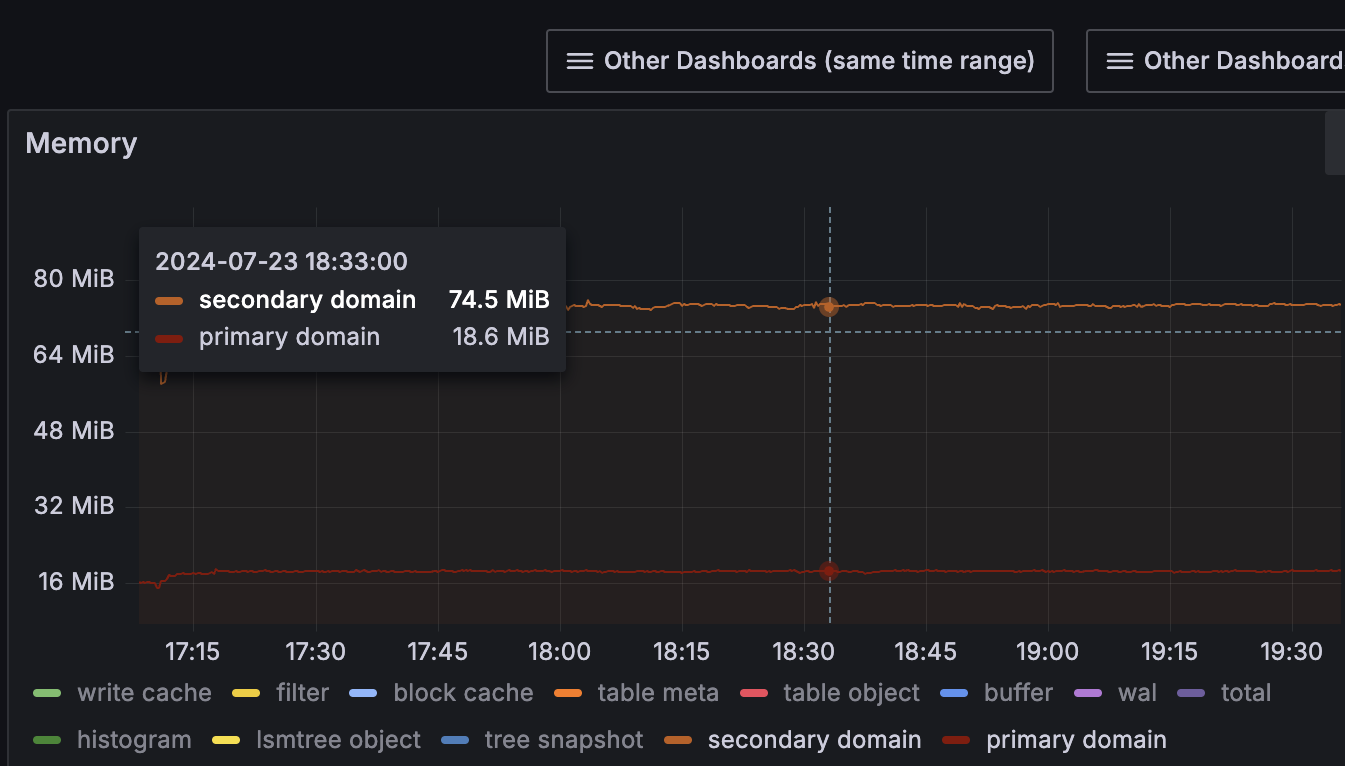
The table meta/table object were also constant as the number of files stays as constant:

This of course trades off available checkpoints for rolling back for lower memory usage. However, at such low scale of datasets, it may be ok to rollback to 0?
Slack discussion thread: