Details
-
Bug
-
Resolution: Unresolved
-
 Major
Major
-
Columnar 1.0.0
-
2239
-
Untriaged
-
0
-
Unknown
Description
- Create a 32 node columnar cluster. Ingest 1B items per remote collection in 20 collections.
- Disconnect previous link and create new link and 20 more collections.
- Start scaling operations from 32 -> 16 -> 8 -> 4 -> 2 -> 4
- Problems started occurring from the last scaling.
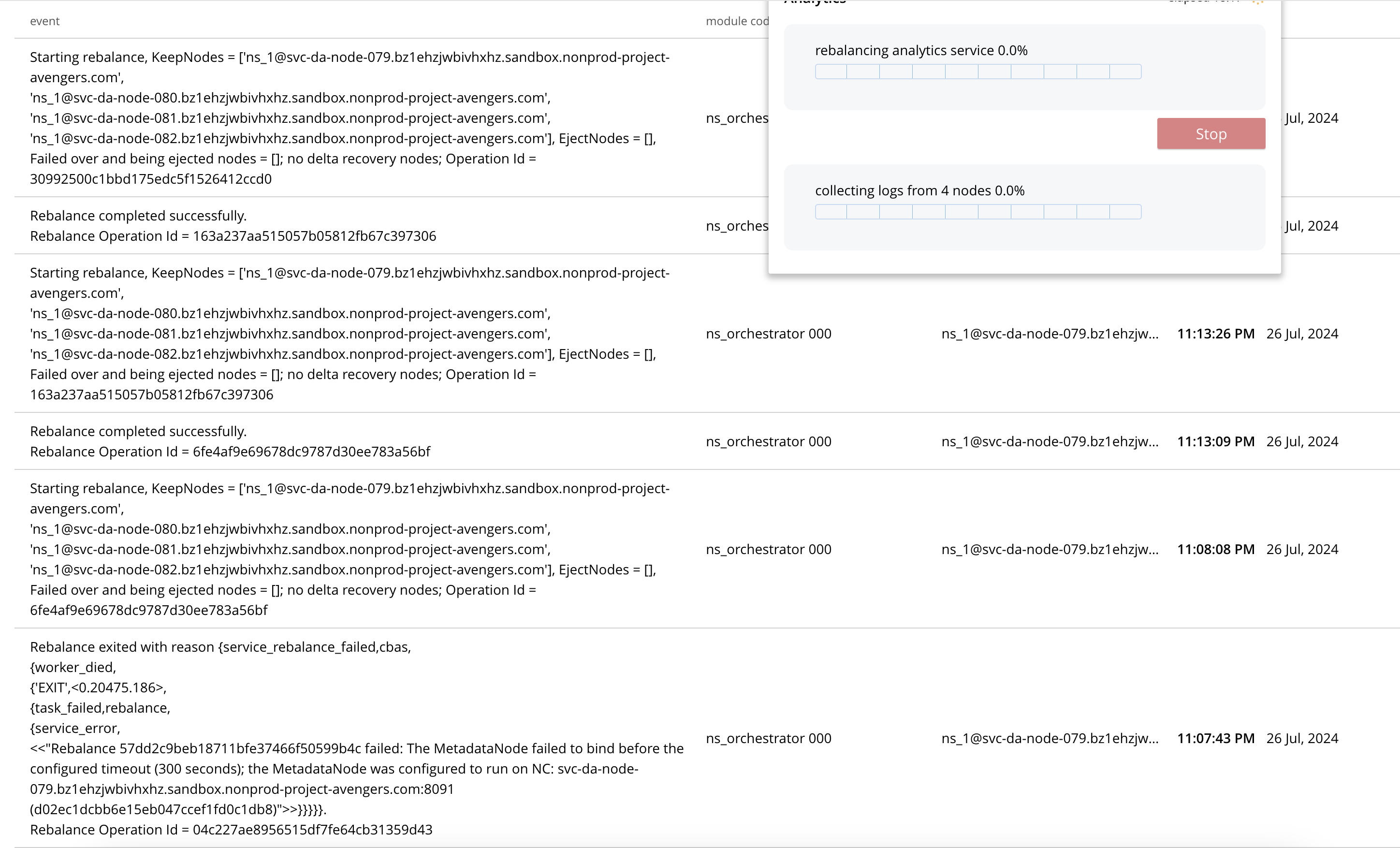
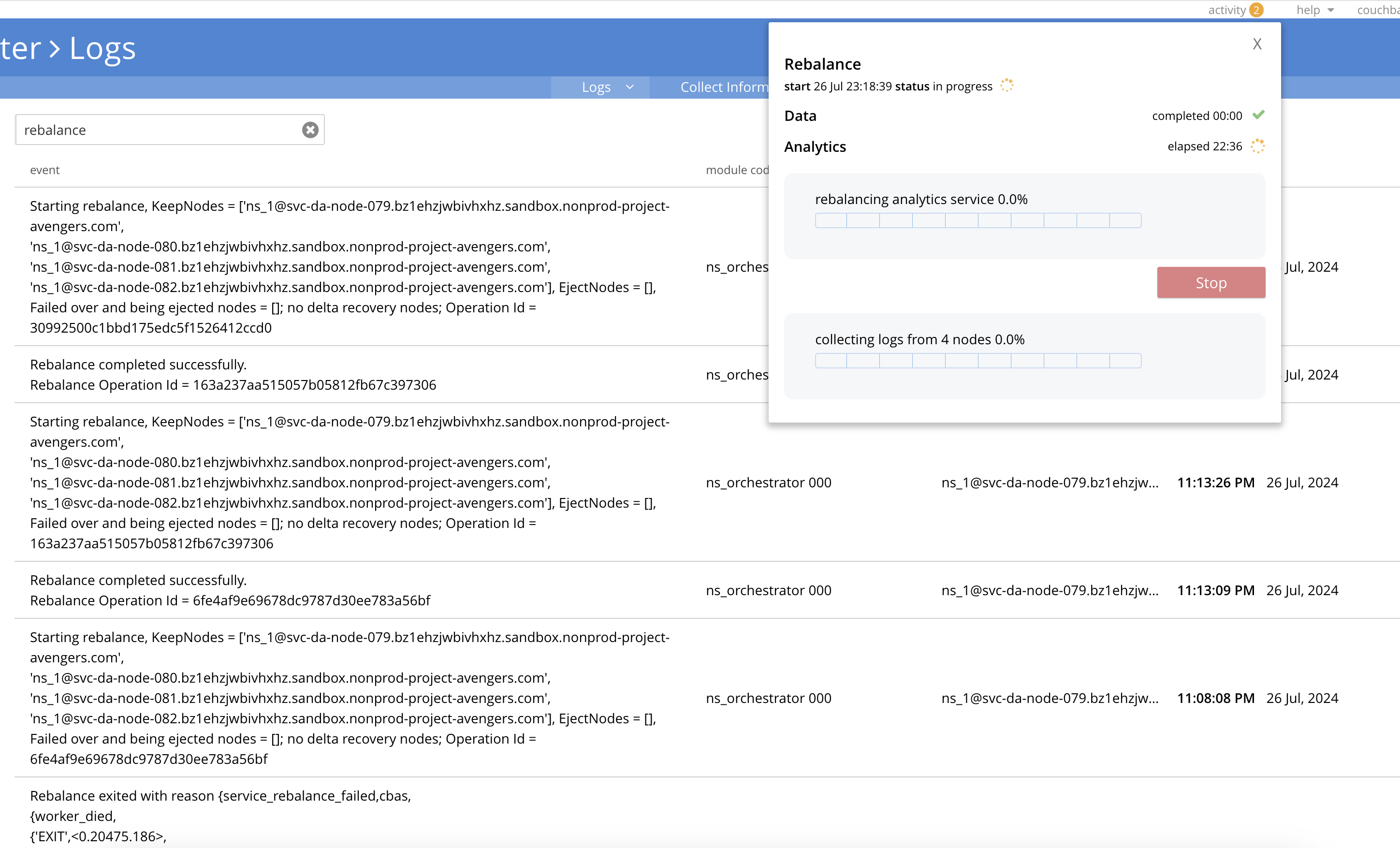
- Rebalance failed but CP reports Healthy
Server
CP:
- CP triggered another rebalance. Not sure why but i guess its due to balance:False state
- Rebalance successful and CP kept on re-triggering.
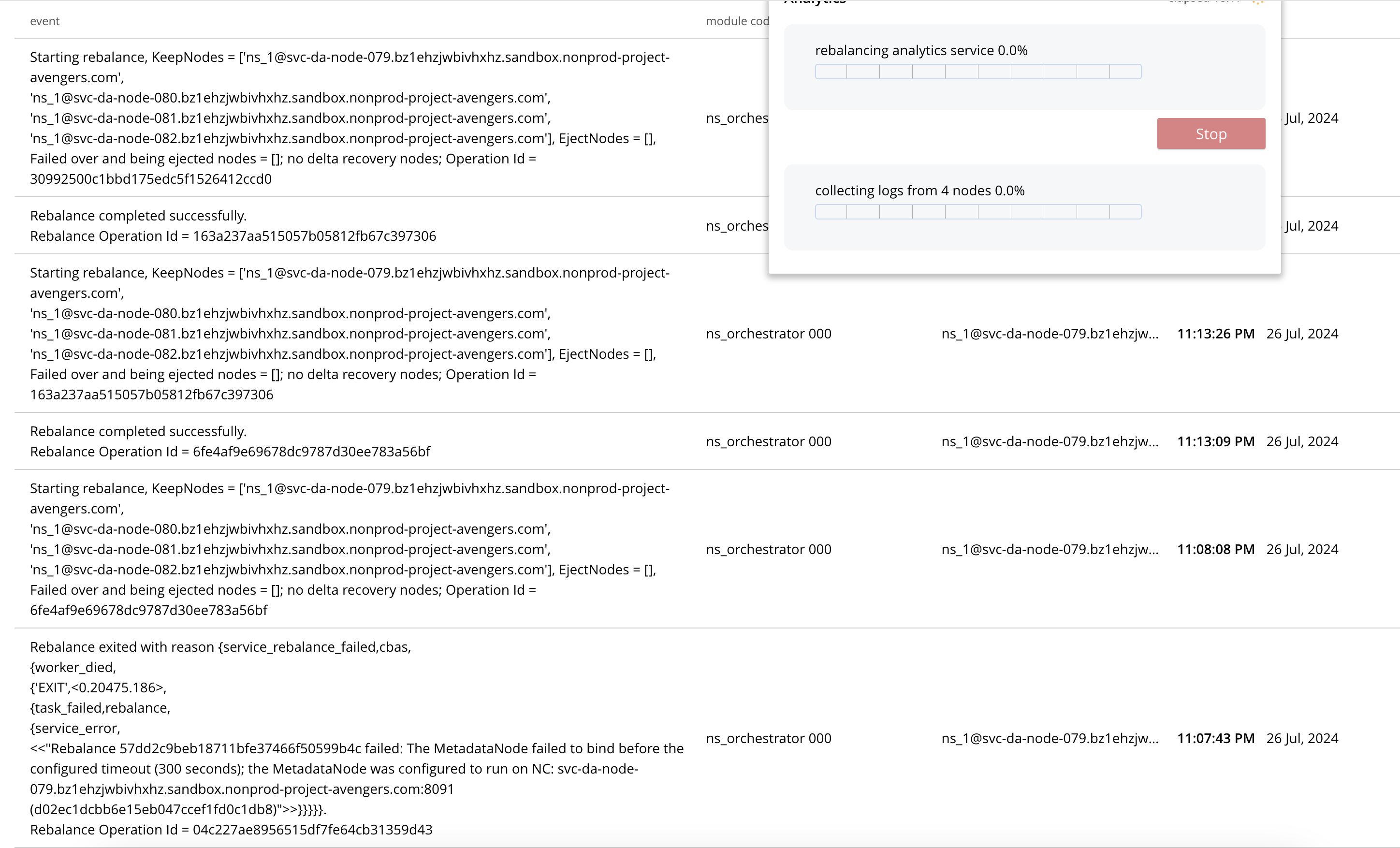
Rebalance exited with reason {service_rebalance_failed,cbas,{worker_died,{'EXIT',<0.20475.186>,{task_failed,rebalance,{service_error,<<"Rebalance 57dd2c9beb18711bfe37466f50599b4c failed: The MetadataNode failed to bind before the configured timeout (300 seconds); the MetadataNode was configured to run on NC: svc-da-node-079.bz1ehzjwbivhxhz.sandbox.nonprod-project-avengers.com:8091 (d02ec1dcbb6e15eb047ccef1fd0c1db8)">>}}}}}.Rebalance Operation Id = 04c227ae8956515df7fe64cb31359d43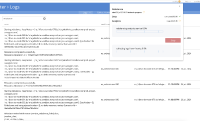
- After 4 successful no-op rebalances finally backend cluster settles down. All this while scaling operation of CP was resulting in 422 error because cluster state healthy allow us trigger next scaling while the cluster is already rebalancing in the bg.
Issues to identify:
- Why did the rebalance failed?
- If the rebalance is failed and CP is retrying then why does CP reports Healthy state?
- Why is CP retrying when rebalance passed on the first rebalance retry attempt?