Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
7.2.6
-
Untriaged
-
-
0
-
Unknown
-
Analytics Sprint 48
Description
Observed in RC-1 for 7.2.6
Test Steps :
- Deployed a GCP cluster with the image =
couchbase-cloud-server-7-2-3-6705-v1-0-25 - Loads Buckets, 1 scope and 5 collections onto it
- Loads docs onto it so the CPU usage goes up
- Triggered a Scale Out to 5 Nodes
- After a successful ScaleOut, Triggered an upgrade to =
couchbase-cloud-server-7-2-6-8101-v1-0-34 - Post successful upgrade, triggers a Scale-In back to 3 nodes.
- Destroys the cluster.
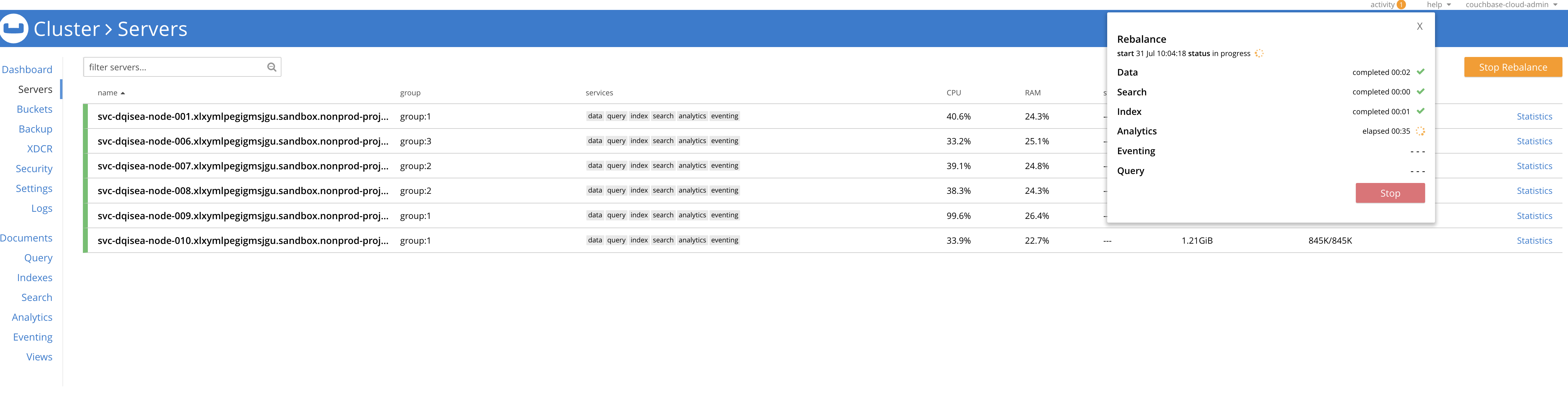
Observations :
- After the scale up step, the upgrade got triggered successfully
- While upgrading, another node got added
- But the cluster is stuck in a repetitive rebalancing state since then
- 6 nodes in the cluster (5 after scale-out & 1 for upgrade rebalance), (Attached)
- One node is in the version 7.2.3-6705 while other 5 have upgraded to 7.2.6-8101
Logs attached below
Server Rebalance Failure Log :
Rebalance exited with reason {service_rebalance_failed,cbas, {worker_died, {'EXIT',<0.7948.630>, {rebalance_failed,
{service_error, <<"Rebalance e211f82a01482b692f206d47baaff1e9 failed: The MetadataNode failed to bind before the configured timeout (60 seconds); the MetadataNode was configured to run on NC: 457650eba6dca7dbe24354bf0809ba20">>}}}}}. Rebalance Operation Id = 4eed05384a65d4ae403fe7d9f1cb443d
UPDATE (RC-2) :
- The same issue has this time been observed on AWS (RC-2)
- Server is stuck in a rebalancing state while it shows `upgrading` status on control plane
- CSP : AWS
- Deploy Version : 7.2.5
- Deploy image : couchbase-cloud-server-7.2.5-7596-x86_64-v1.0.32
- Upgrade version : 7.2.6
- Upgrade image : couchbase-cloud-server-7.2.6-8103-x86_64-v1.0.34
- Rebalance while upgrading has been stuck due to dead worker on cbas service.
Specific AWS Server Log :
Rebalance exited with reason {service_rebalance_failed,cbas, {worker_died, {'EXIT',<0.32519.440>, {rebalance_failed,
{service_error, <<"Rebalance 06a51d6ef1ef6f212c2a09d93bfe5982 failed: The MetadataNode failed to bind before the configured timeout (60 seconds); the MetadataNode was configured to run on NC: d41a1deddf76ef20fd12c784cd8afeca">>}}}}}. Rebalance Operation Id = 7274b73c693b68ff270ebfd194f559dc