Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
2.0-beta-2
-
Security Level: Public
-
None
-
2.0.0-1835-rel
Ubuntu EC2
10 (west coast) : 10 (south east)
standard bucket :: west -> southeast
default :: southeast -> west
Description
- Set up 2 unidirectional replications either way on the 2 clusters (mentioned).
- After load and replication of about 75M+ items on the standard bucket and 45M+ items on the default bucket,
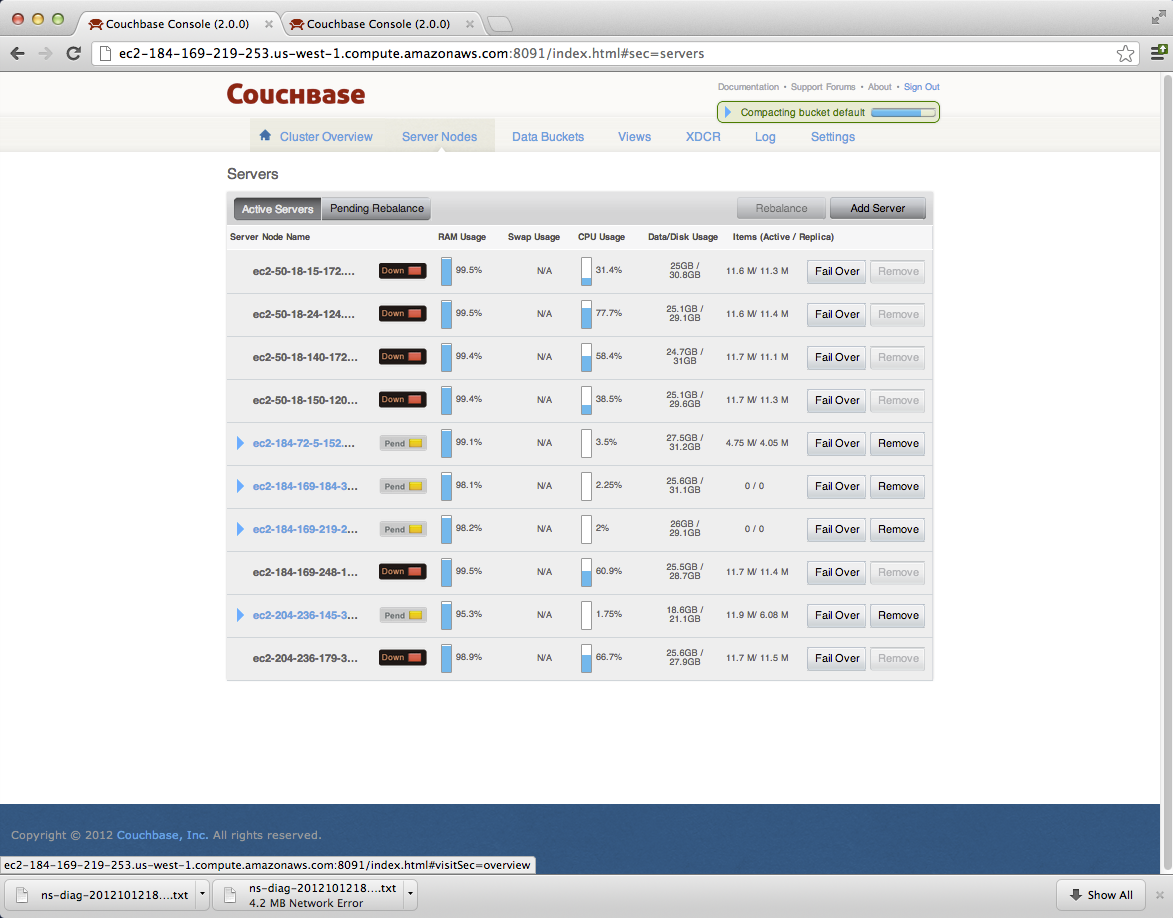
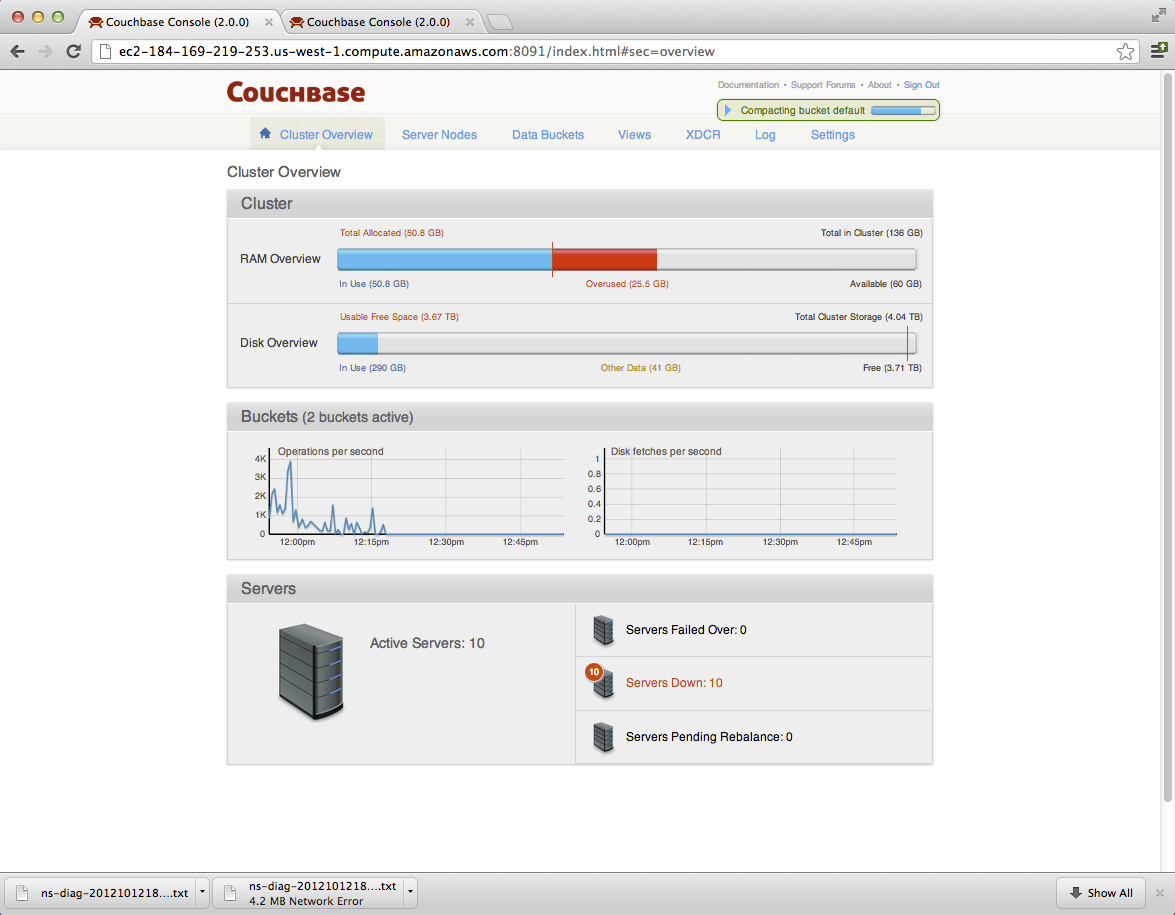
it started with a few nodes and then gradually all of them on cluster1 (west coast): nodes started going down. - Couchbase-server seemed to be running still on each of them.
- It was seen that some of these nodes were warmed up (for unknown reasons), and after the warmup, ns_server couldn't connect to the vbuckets, leaving many of them in a dead state.
The ATOP information on one of the nodes that went down (c1):
24830 couchbas 20 0 3717m 3.4g 1956 S 14 23.4 2:53.76 memcached
9590 couchbas 20 0 3095m 1.4g 1648 S 10 9.8 1040:28 beam.smp
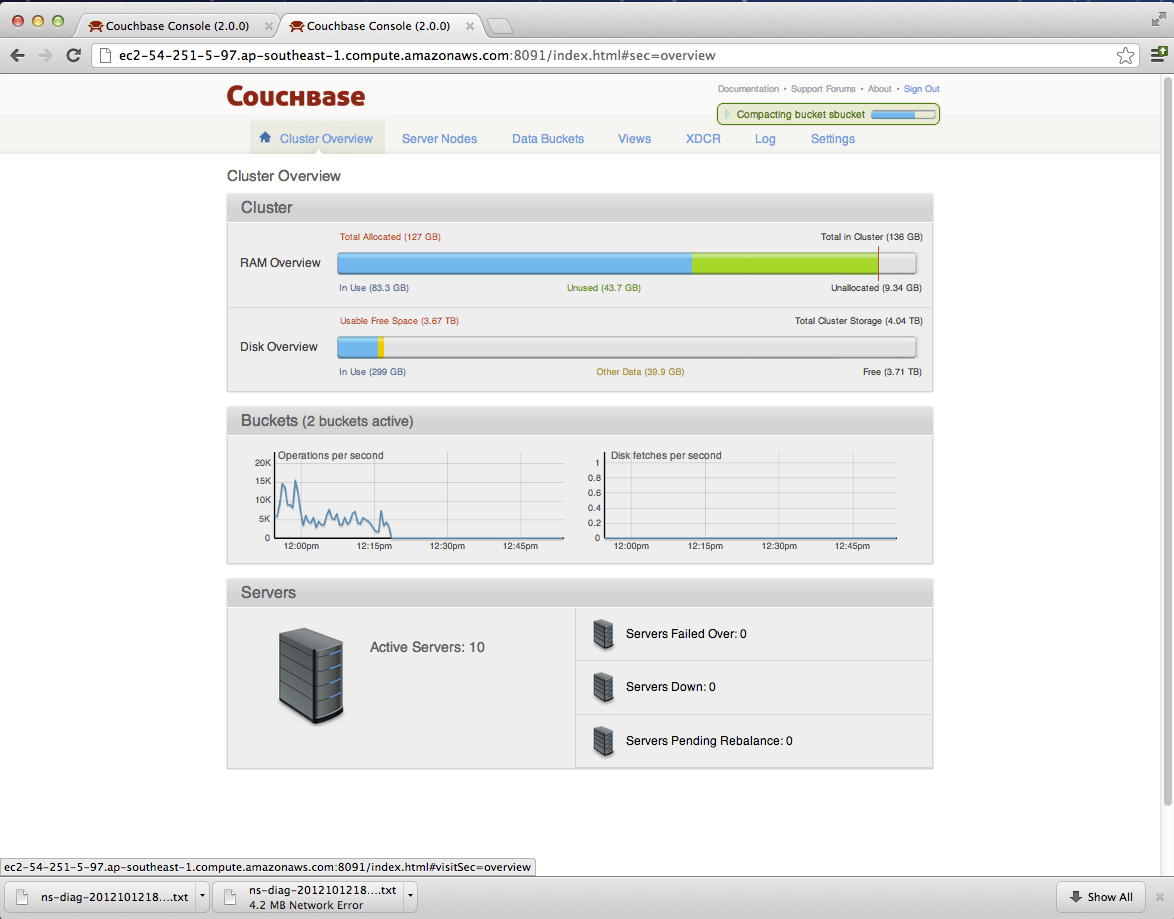
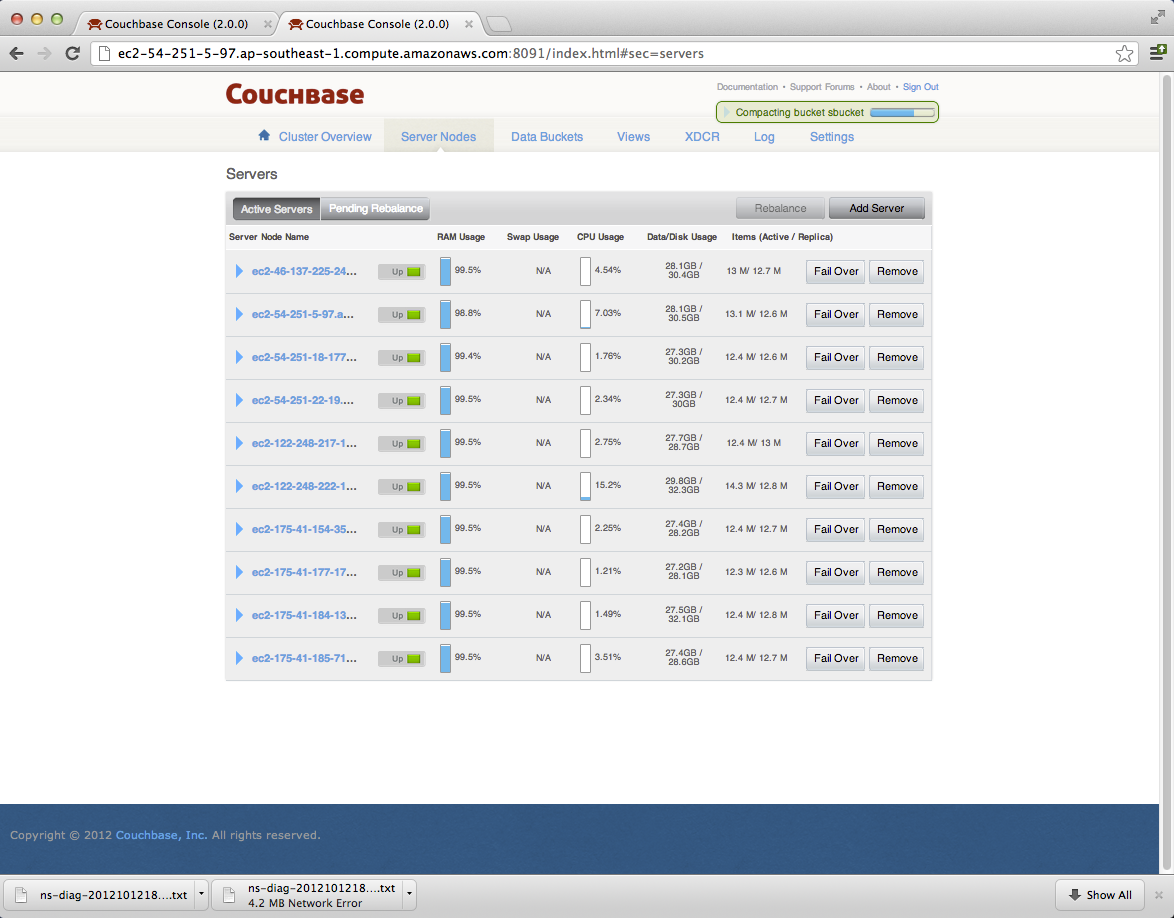
Was able to grab the diags of a few nodes before all of them went down (attached).
c1: http://ec2-184-169-219-253.us-west-1.compute.amazonaws.com:8091/
c2: http://ec2-54-251-5-97.ap-southeast-1.compute.amazonaws.com:8091/