Description
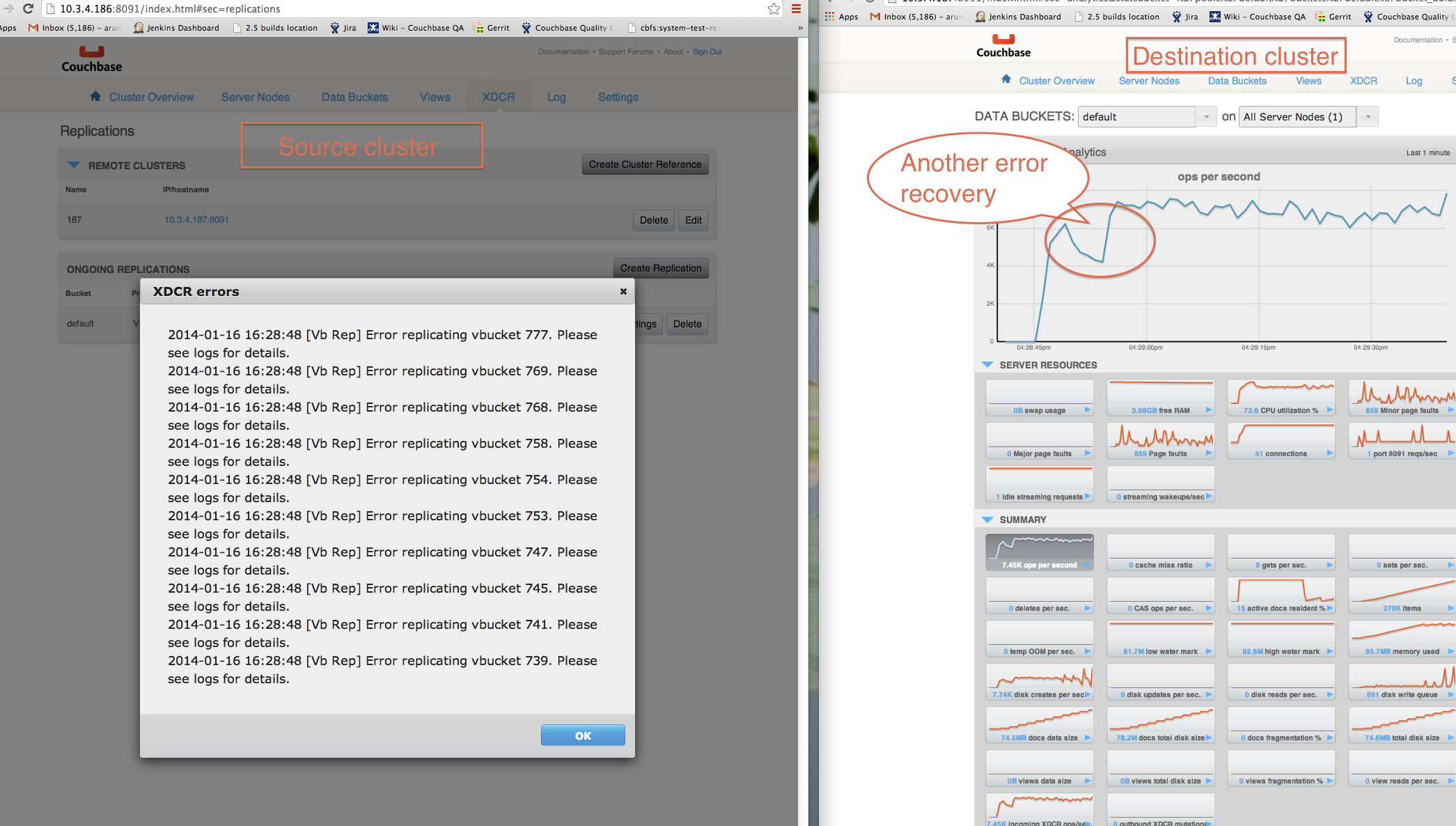
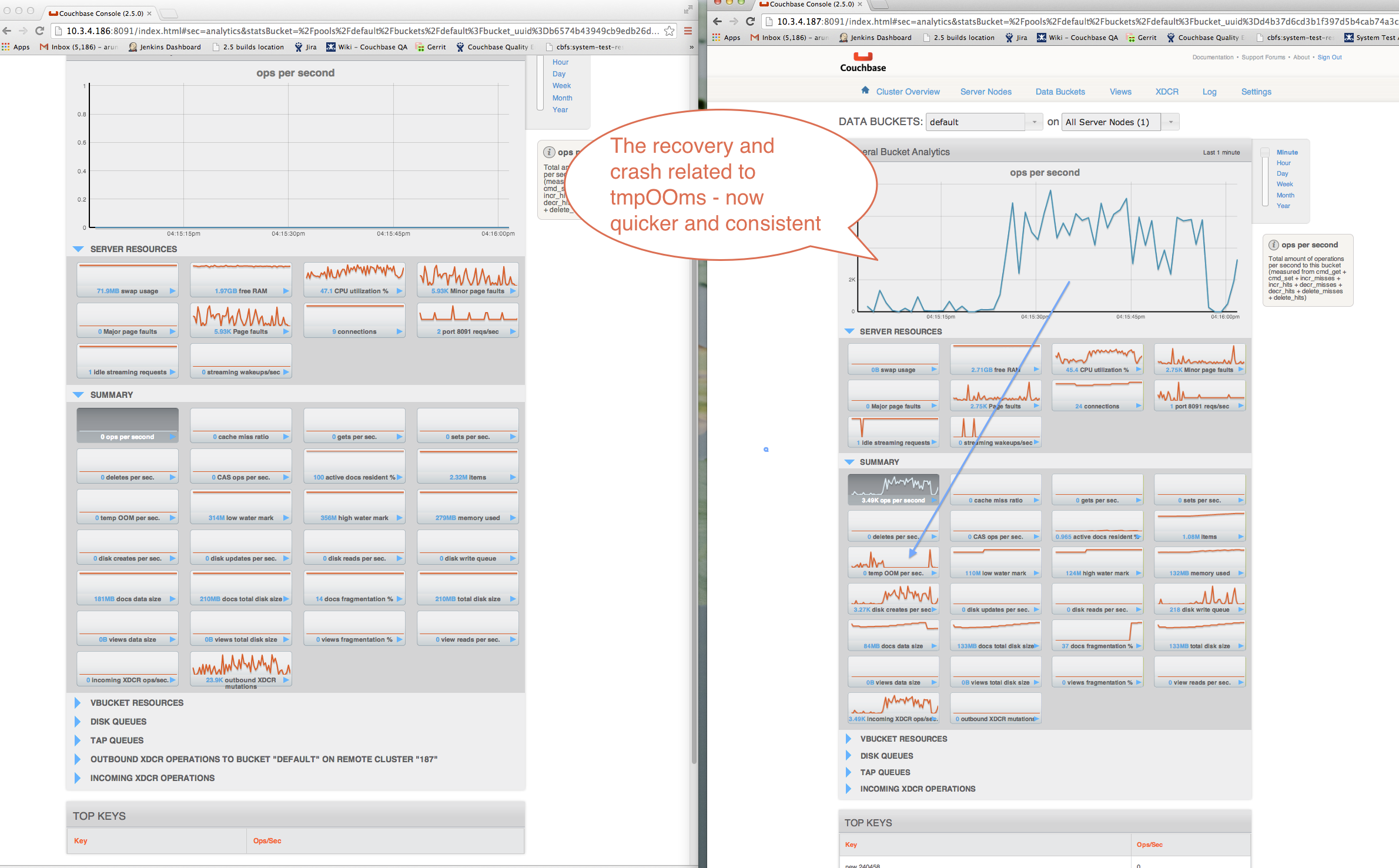
easiest way to introduce this is by forcing the server into heavy tmp_oom which causes the streams to crash and restart (expectedly). The problem is that while they should all restart very quickly, the whole set can take up to a few minutes.
To reproduce:
-Setup 2 4-node clusters with the beer-sample database
-Link that bucket in a bi-directional replication with settings:
-version 1 or version 2 (need to test both to make sure the fix applies to both)
-Replicators: >128 (I know it's high, but this is where we see the issue most easily)
-Restart interval: 1s (you can leave it at the default of 20s which shows the same problem, but 1s makes it more obvious and "finishes" faster)
-Optimistic threshold: 11000 (don't know if this is important, but it's how I've been running the test)
-Run the following workload from two separate clients, against each bucket simultaneously:
(using libcouchbase-bin...it shouldn't really matter what you use, but this is my test)
Client1: cbc pillowfight --host <cluster1> -b beer-sample --num-threads 4 --min-size 10240 --max-size 10240 --ratio 50 -Q 4 -I 30000
Client2: cbc pillowfight --host <cluster2> -b beer-sample --num-threads 4 --min-size 10240 --max-size 10240 --ratio 50 -Q 4 -I 20000
(notice that client1 puts in 30k items, while client2 puts in 20k...this is important to notice the difference in item counts)
-You will quickly observe that many sets fail with temporary failures. This is okay and expected
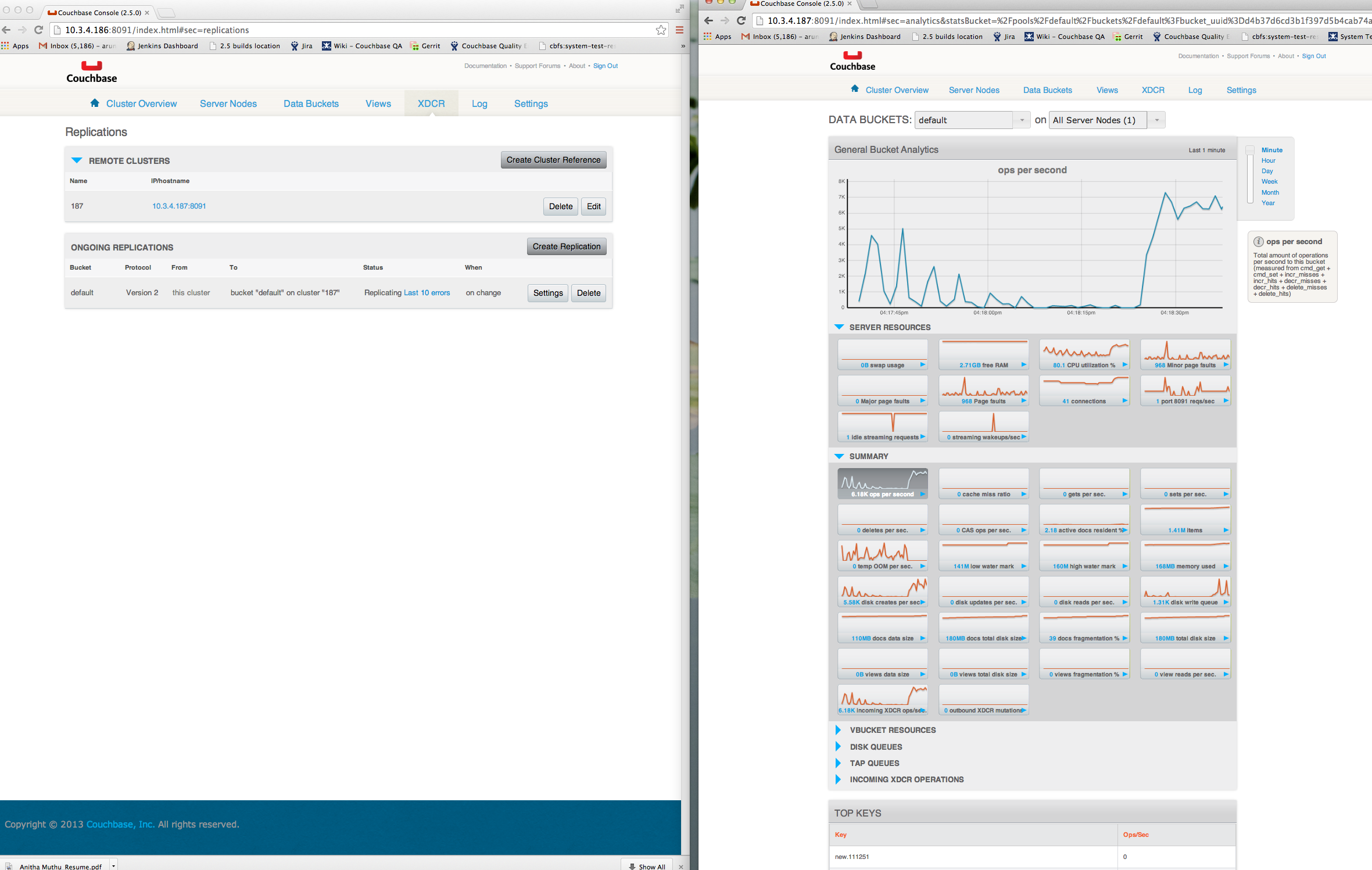
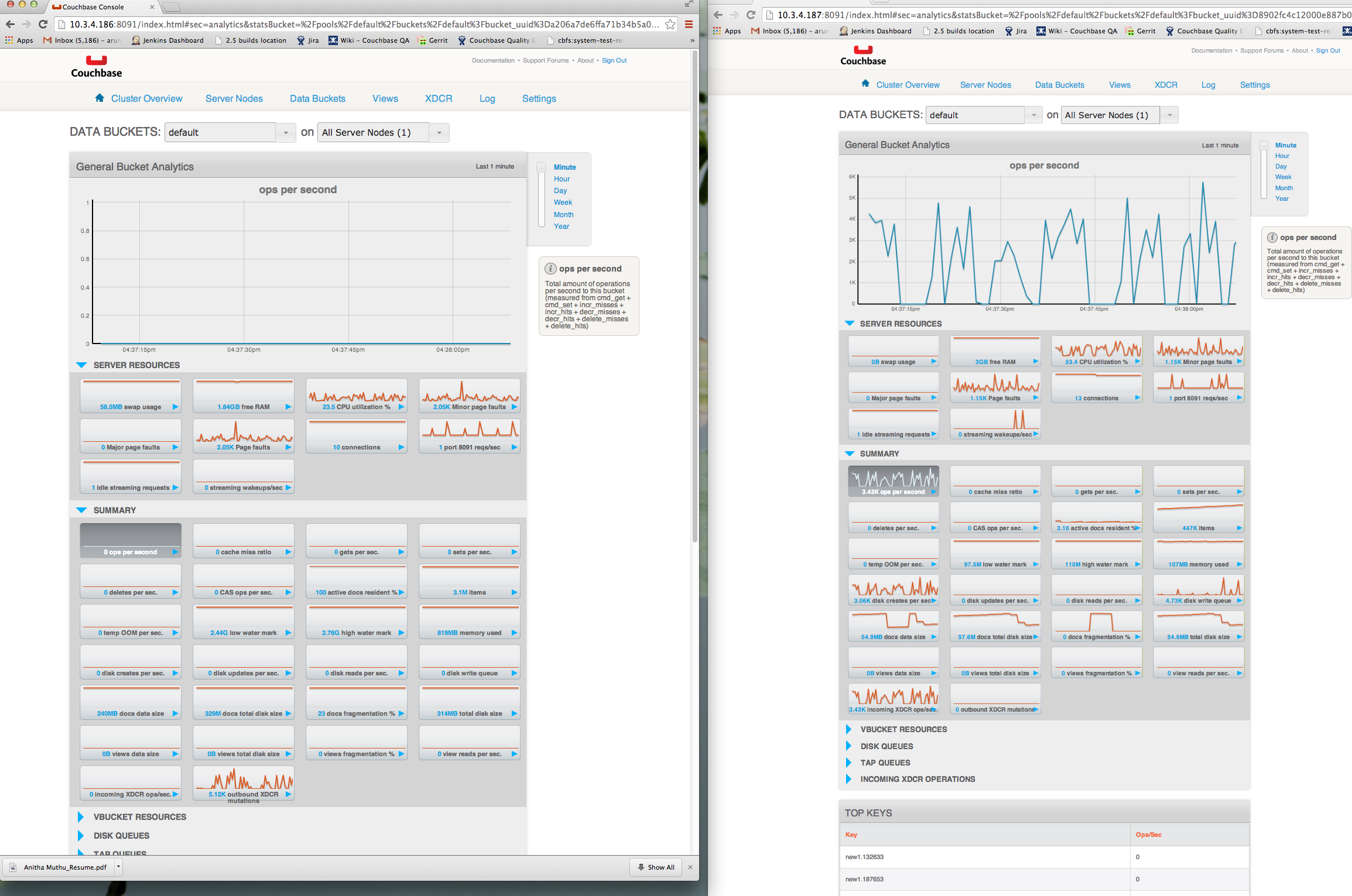
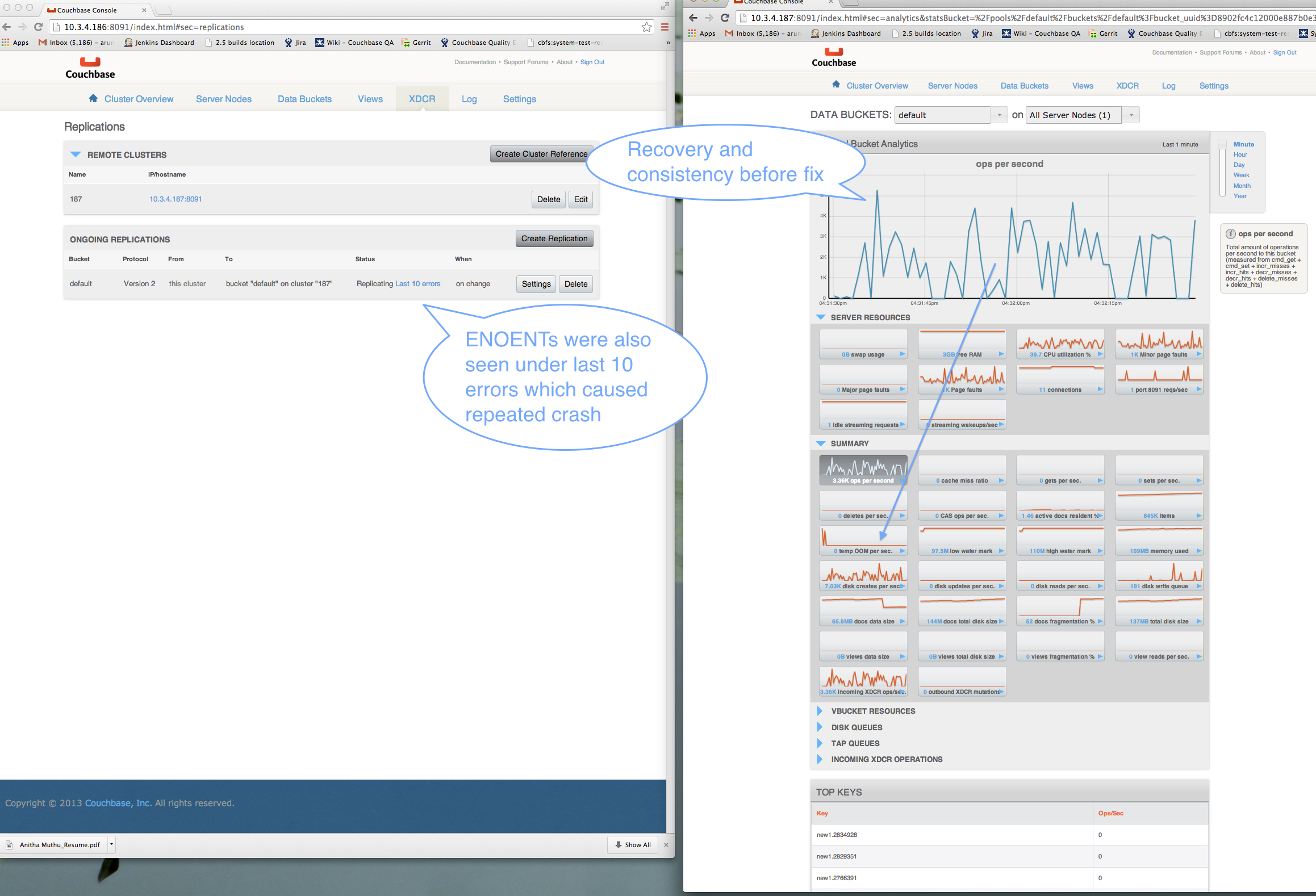
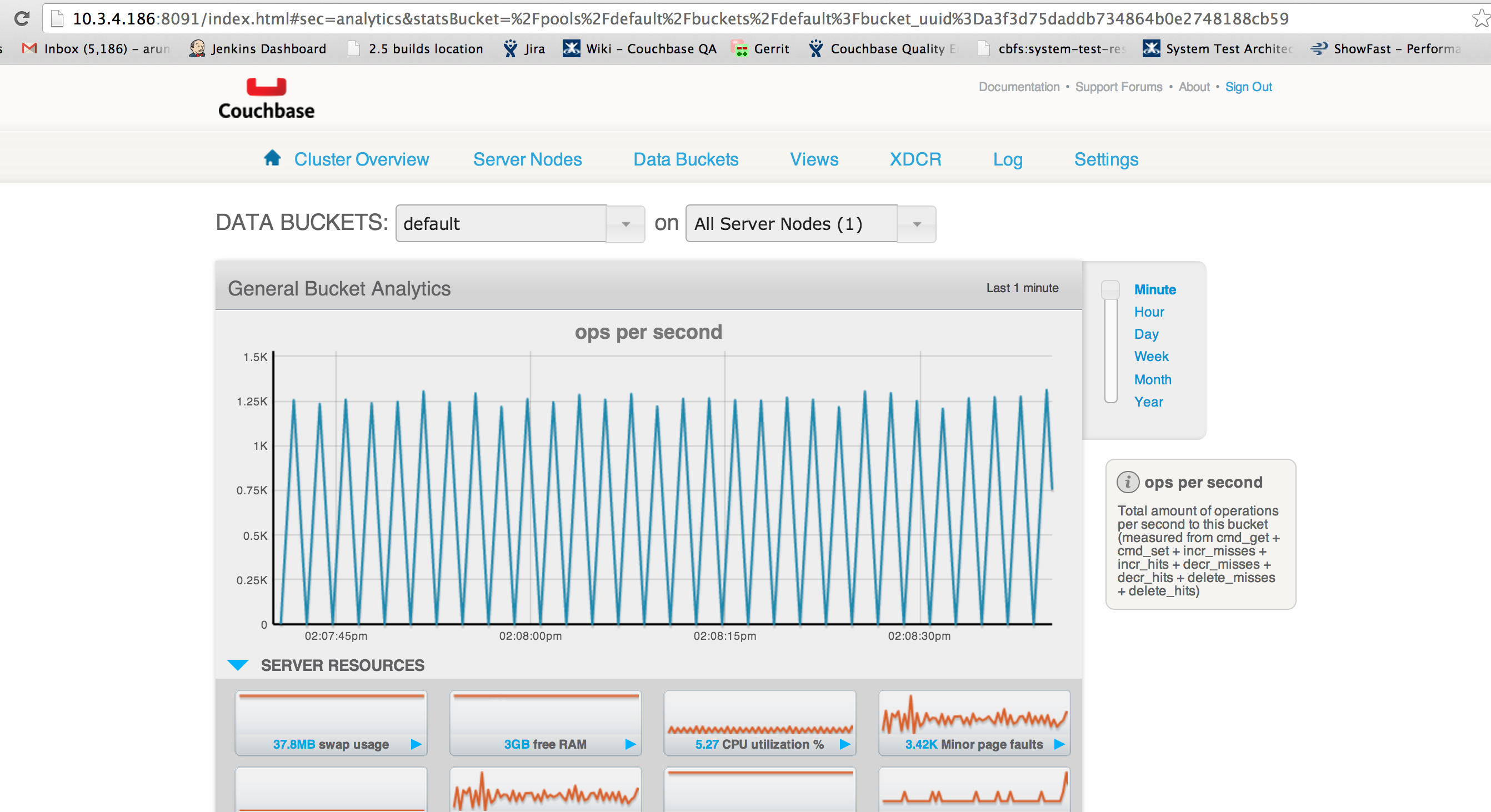
Once the disk write queue has finished raining, you will observe lots more XDCR traffic in very "spikey" intervals, going from 0 ~200 items/sec being transferred once per second
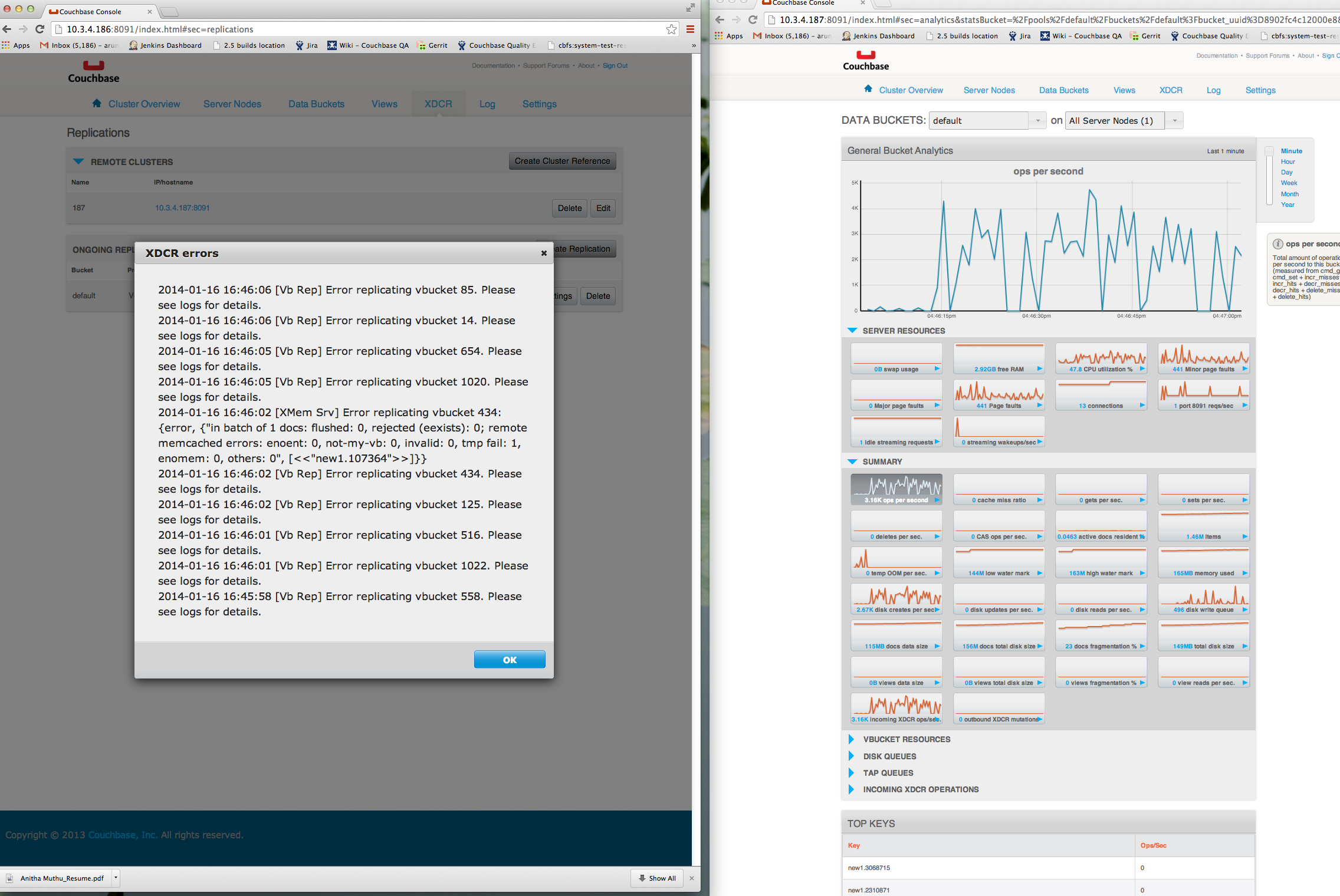
-You will also notice that the item counts do not match and only finished synchronizing many minutes after the workload has stopped
The high level issue is that we would not expect it to take so much longer for the item counts to catch up.
I'm adding both xdcr and ns_server, though Junyi has verified that the XDCR code is doing "the right thing" by asking a stream to restart within it's interval and now the suspicion is that ns_server is somehow either not scheduling them to restart all at once or in some other way delaying.
I've reproduced this with both CAPI and XMEM, CAPI only on 2.2 (because XMEM had another bug there), and both on 2.5-1007
These logs are using bi-directional xmem, with 256 replicators, 30s restart interval and optimistic threshold of 11000 (the steps below change this slightly but the numbers don't affect the overall behavior):
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster1node1.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster1node2.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster1node3.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster1node4.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster2node1.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster2node2.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster2node3.zip
http://s3.amazonaws.com/customers.couchbase.com/cbse_898/2.5.0_1007xmemcluster2node4.zip
In this output, the XMEM XDCR stream was created at "2013-12-11T10:51:28.327", the workload started right after that and the workload finished sometime before 2013-12-11T10:53:48.422...the XDCR synchronization continues for a few minutes after.
Attachments
Issue Links
- is duplicated by
-
MB-9707 users may see incorrect "Outbound mutations" stat after topology change at source cluster (was: Rebalance in/out operation on Source cluster caused outbound replication mutations != 0 for long time while no write operation on source cluster)
-

- Closed
-
- relates to
-
-

- Closed
-