Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
3.0-Beta, 3.0, 3.0.1, 3.0.2
-
Security Level: Public
-
Platform = Physical
OS = CentOS 6.5
CPU = Intel Xeon E5-2630 (24 vCPU)
Memory = 64 GB
Disk = RAID 10 HDD
-
Triaged
-
Yes
Description
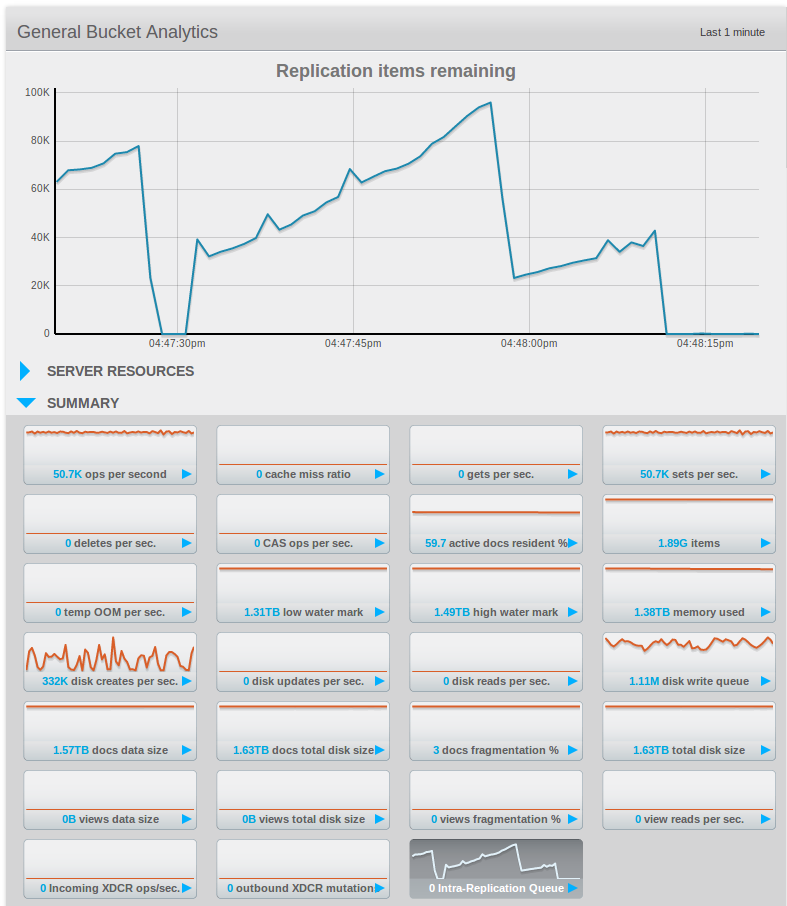
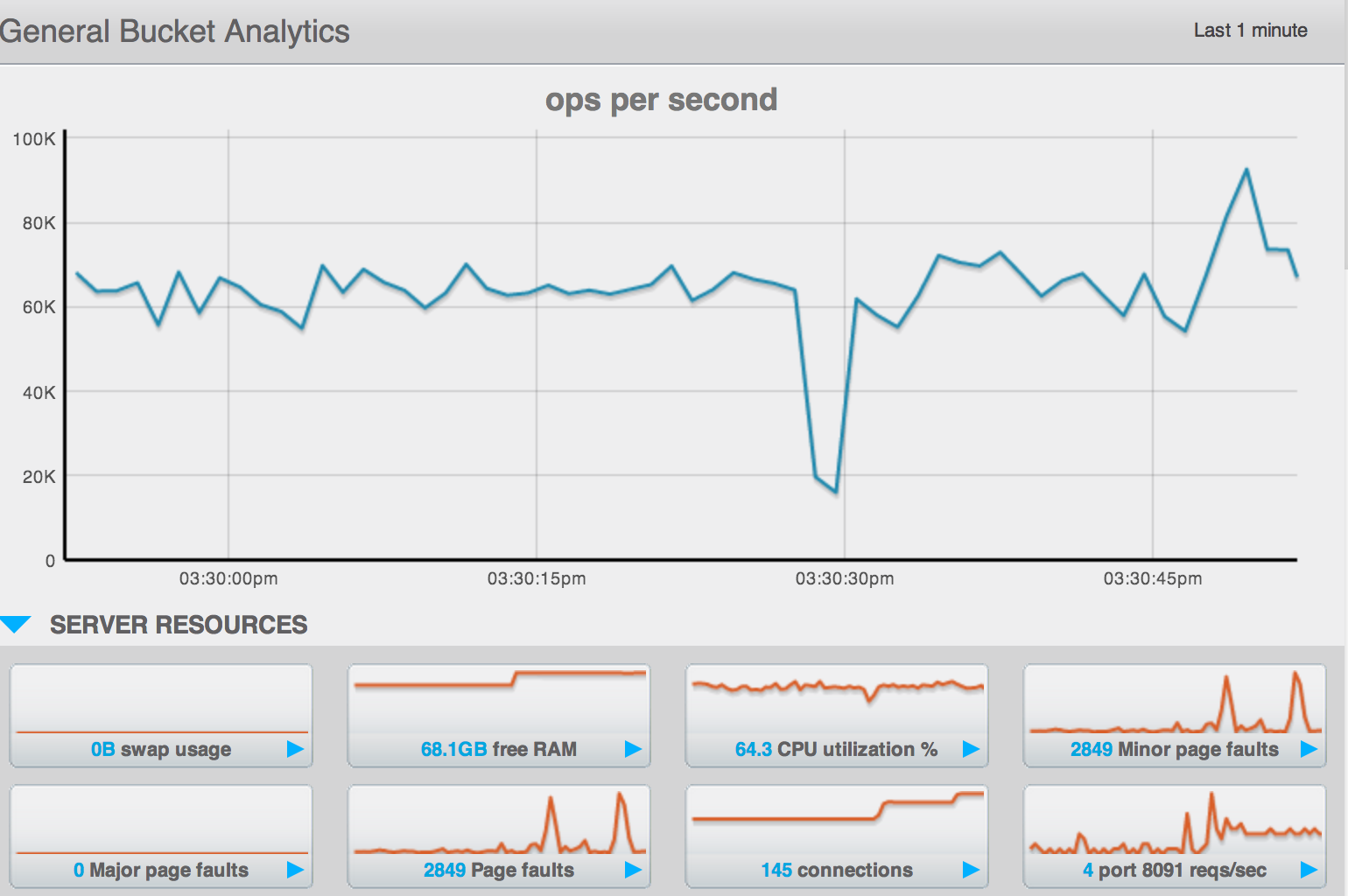
Running the "standard sales" demo that puts a 50/50 workload of about 80k ops/sec across 4 nodes of m1.xlarge, 1 bucket 1 replica.
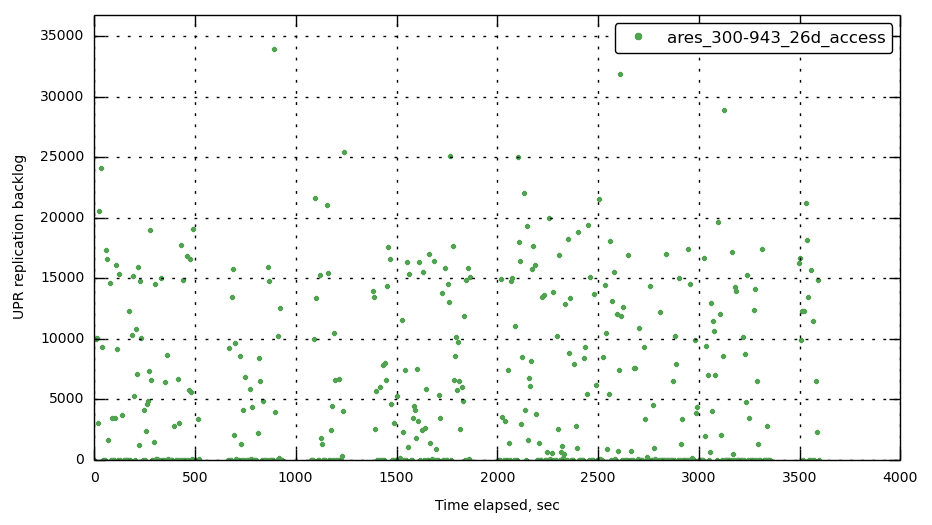
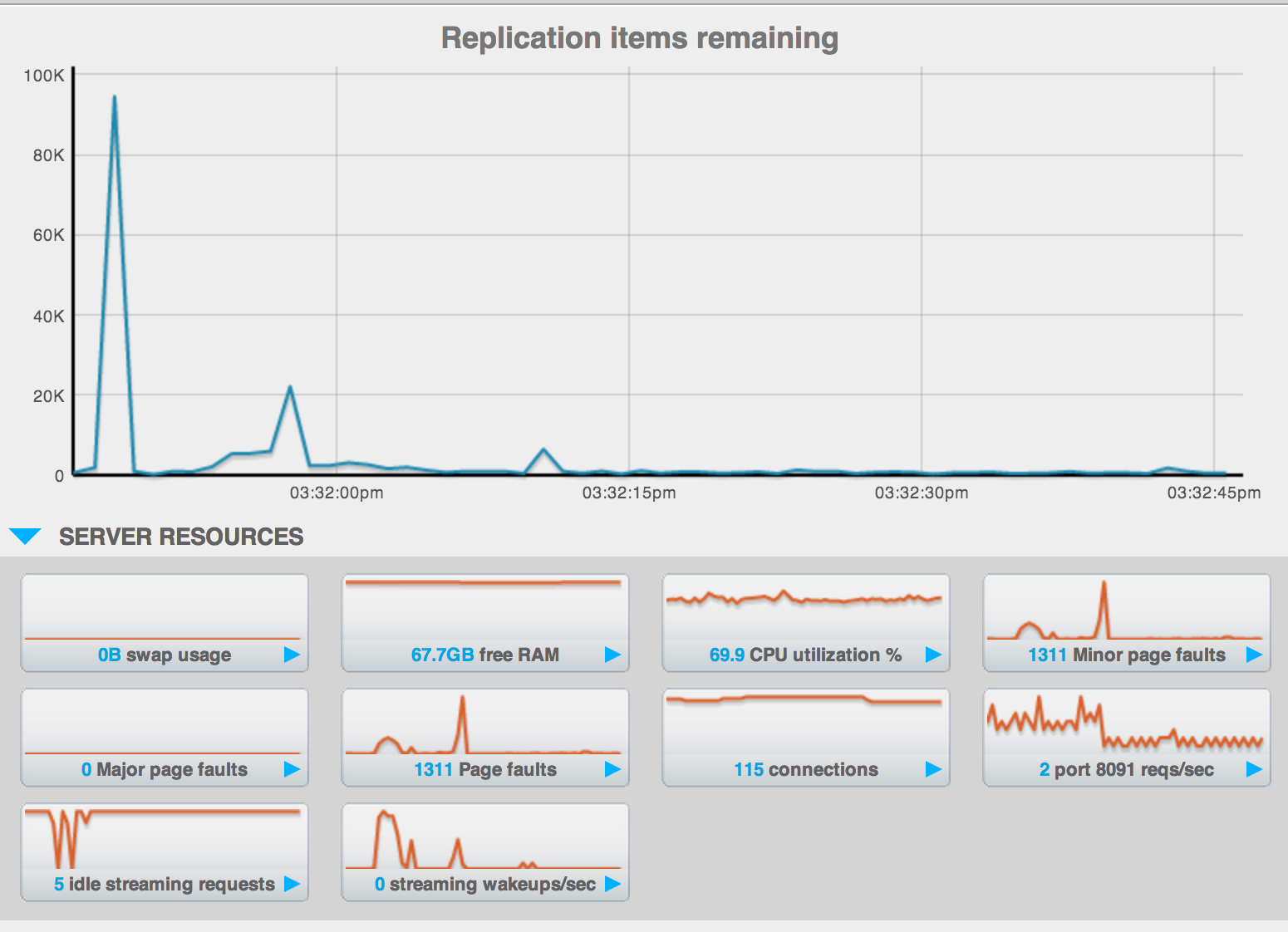
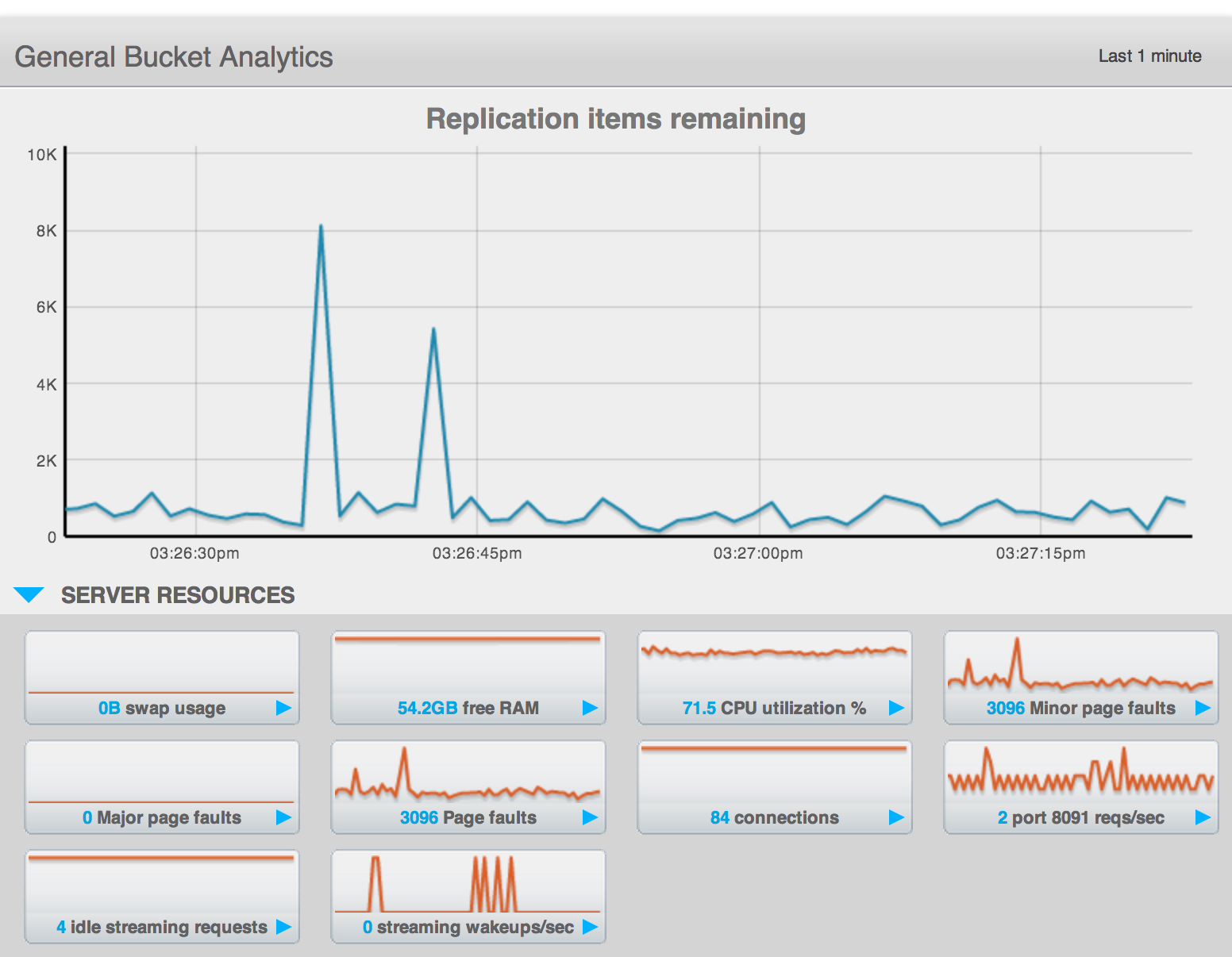
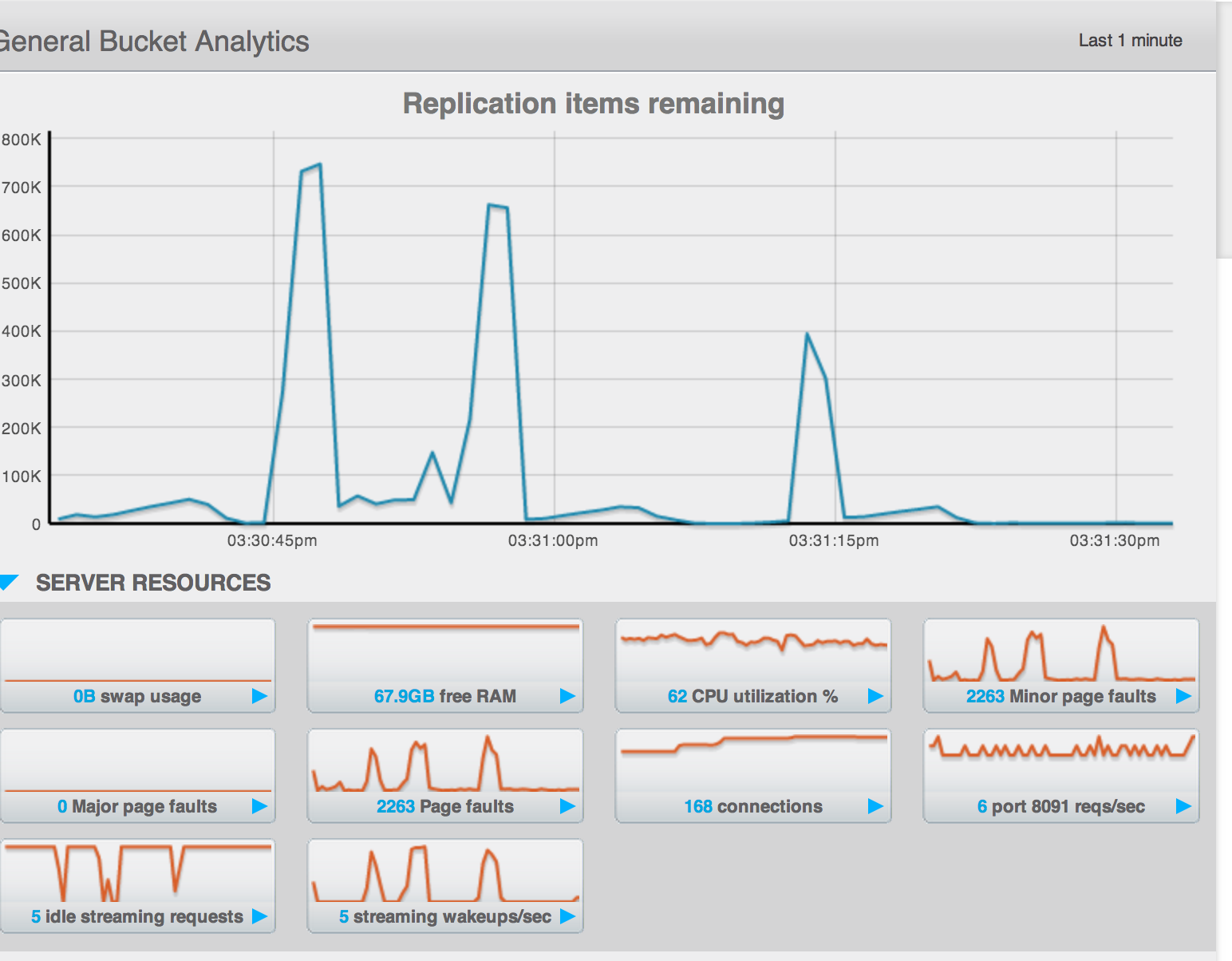
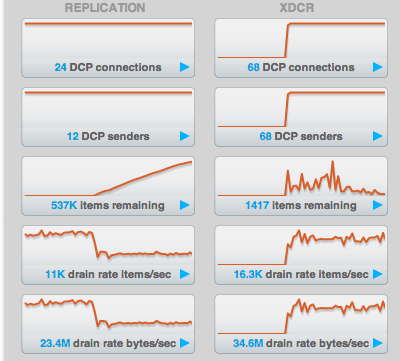
The "intra-cluster replication" value grows into the many k's.
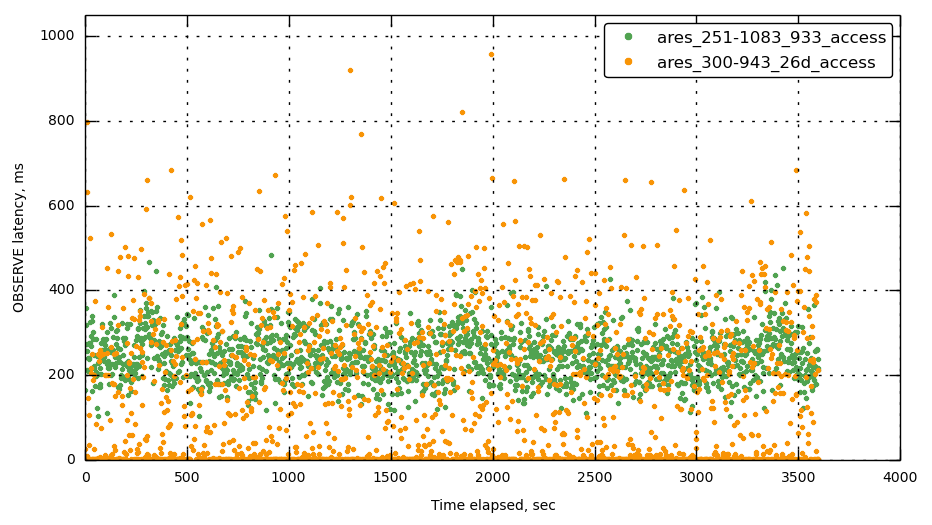
This is a value that our users look rather closely at to determine the "safety" of their replication status. A reasonable number on 2.x has always been below 1k but I think we need to reproduce and set appropriate baselines for ourselves with 3.0.
Assigning to Pavel as it falls into the performance area and we would likely be best served if this behavior was reproduced and tracked.
Attachments


Issue Links
- blocks
-
MB-17211 4.1.1 Minor Release
-
- Closed
-
- relates to
-
-

- Resolved
-
-
MB-11640 Provide ability to set the DCP stream priority (low/high)
-
- Resolved
-
-
-

- Closed
-
-
-
- Closed
-
- mentioned in
-
Page Loading...
| For Gerrit Dashboard: MB-11642 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 40392,10 | MB-11642 Batch load dcp mutations if replication | master | ep-engine | Status: MERGED | +2 | +1 |
| 40629,1 | thread debug for MB-11642 | master | ep-engine | Status: ABANDONED | 0 | 0 |
| 41757,8 | MB-11642: Allow changes to tap/dcp batch size | 3.0.1 | memcached | Status: MERGED | +2 | +1 |
| 41758,3 | MB-11642: Change the priority based on the type of dcp connection | 3.0.1 | ep-engine | Status: MERGED | +2 | +1 |
| 41811,1 | Merge remote-tracking branch 'membase/3.0.1' | master | memcached | Status: MERGED | +2 | +1 |
| 43047,2 | Backport of fix for MB-11642 | 3.0 | memcached | Status: MERGED | +2 | +1 |
| 46781,1 | Merge remote-tracking branch 'couchbase/sherlock' | master | memcached | Status: MERGED | +2 | +1 |
