Details
-
Bug
-
Resolution: Fixed
-
 Blocker
Blocker
-
3.0
-
Security Level: Public
-
Platform = Physical
OS = CentOS 6.5
CPU = Intel Xeon E5-2680 v2 (40 vCPU)
Memory = 256 GB
Disk = RAID 10 SSD
-
Untriaged
-
Centos 64-bit
-
Yes
-
June 30 - July 18
Description
5 -> 5 UniDir, 2 buckets x 500M x 1KB, 10K SETs/sec, LAN
This is not a new problem, we could observe it for many months.
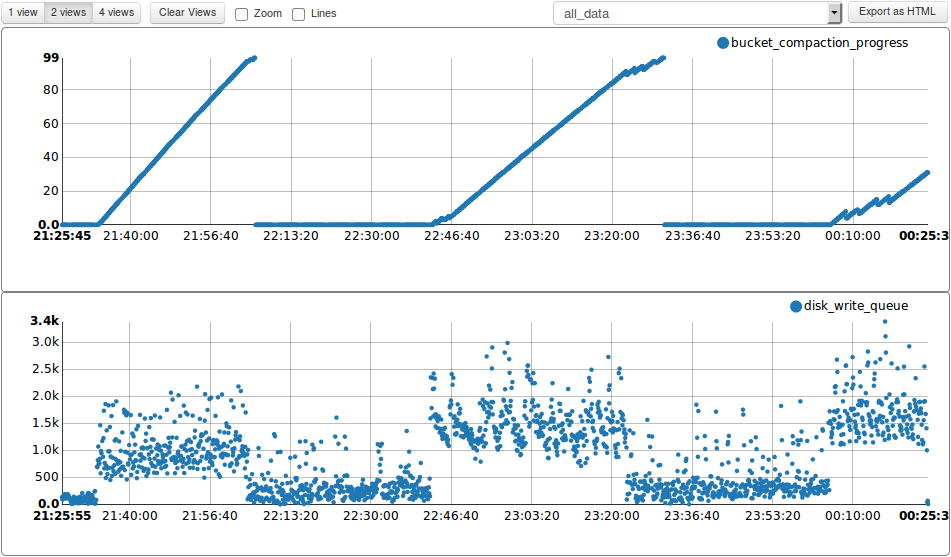
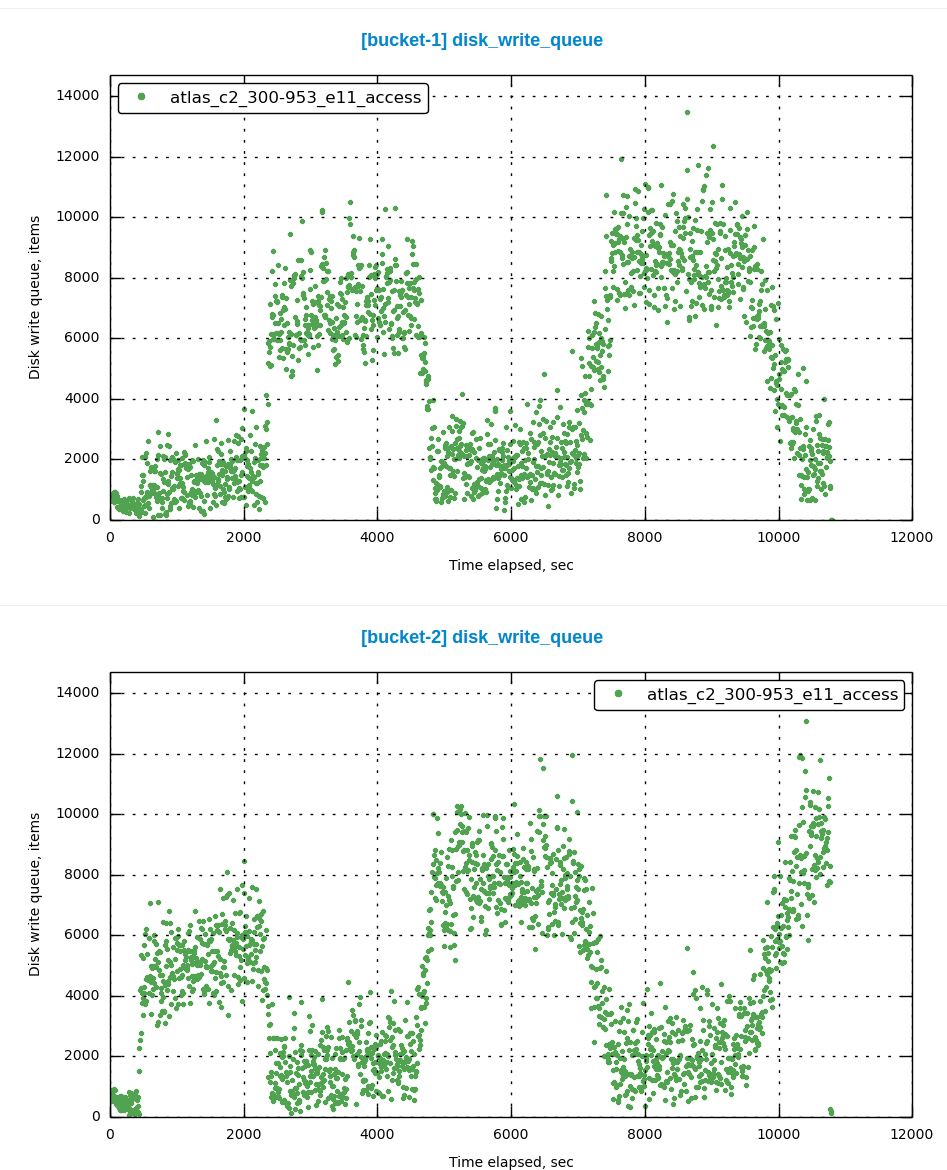
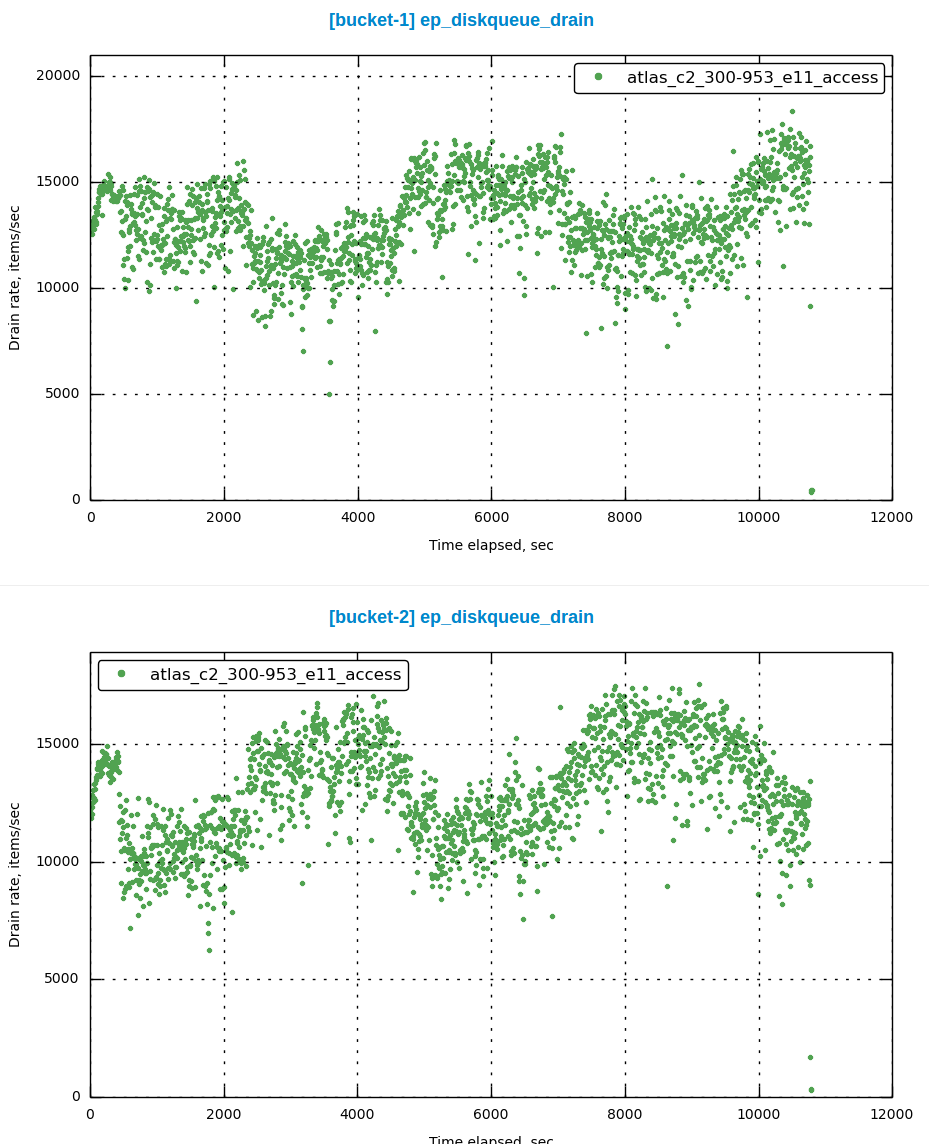
From attached charts you can see that drain rate (and disk write queue correspondingly) are antiphased, every 30-40 minutes one of buckets drains faster.
On average size of disk write queue doesn't differ from 2.5.x but peak values are slightly higher.
Attachments
Issue Links
| For Gerrit Dashboard: MB-11731 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 34501,11 | MB-11731: Vbucket-level locking as opposed to shard-level | master | ep-engine | Status: MERGED | +2 | +1 |
| 39502,6 | MB-11731 remove shard level locking from ExecutorPool | master | ep-engine | Status: MERGED | +2 | +1 |
| 39647,3 | MB-11731 compact vbuckets in parallel | master | ns_server | Status: MERGED | +2 | +1 |
| 39906,3 | MB-11731 Replace the shard-level vbstate snapshot with individual tasks. | master | ep-engine | Status: MERGED | +2 | +1 |
| 39907,3 | MB-11731 Add the daemon vbucket state snapshot task. | master | ep-engine | Status: MERGED | +2 | +1 |
| 39910,3 | MB-11731 Reduce the lock overhead among flusher, VB deletion, and compaction | master | ep-engine | Status: MERGED | +2 | +1 |