Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
4.5.0
-
None
Description
We need to improve the parsing capabilities of the parser used by the projector and query engine.
Problem
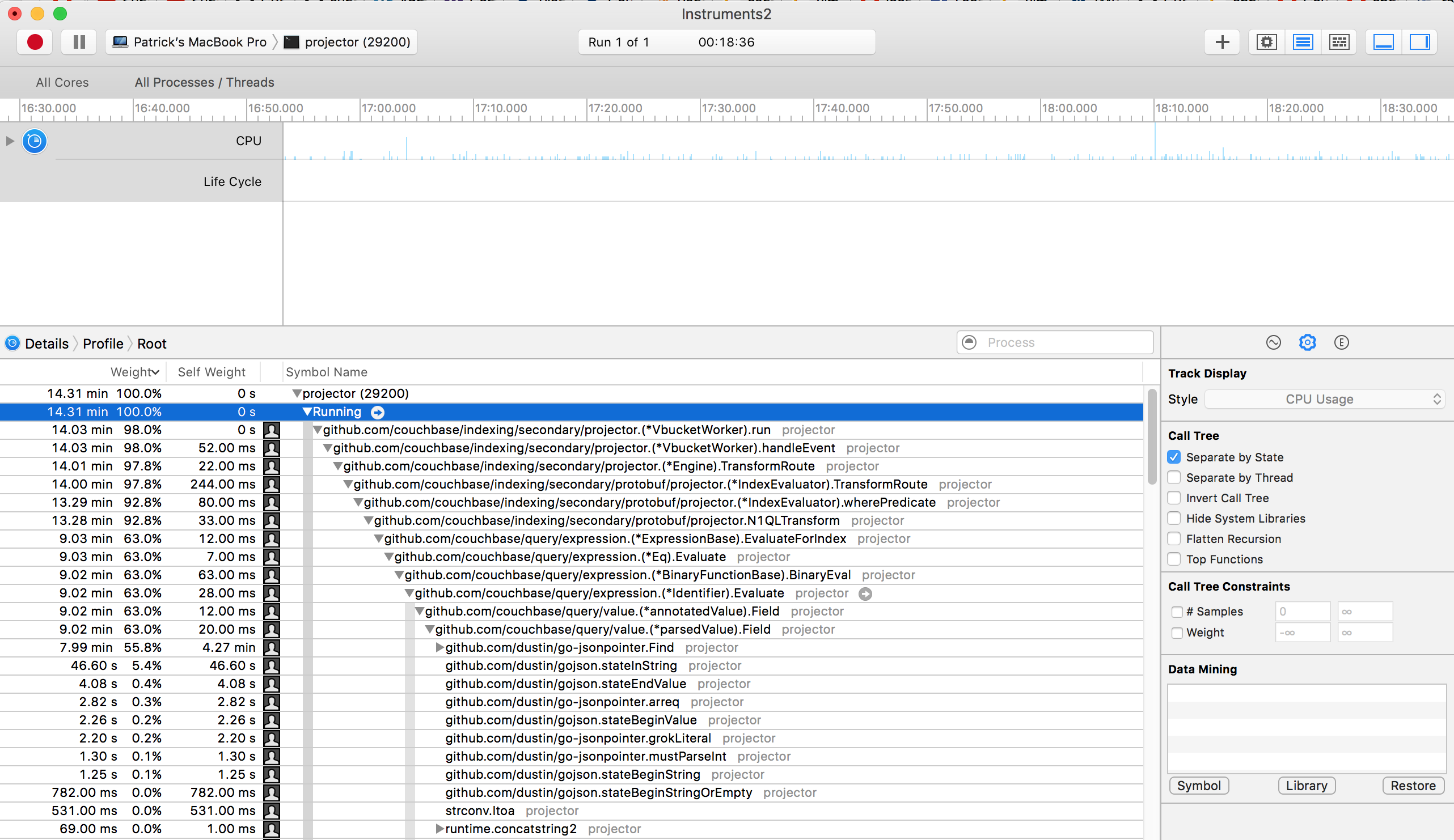
In document size over 180KB with 90 mutations per second and 20 indexes with a number of different WHERE clauses the projector can use a lot of CPU.
Expectation
That the projector can process data as efficiently as possible
Work Around
To avoid using WHERE clauses with large document and see if the same logical can be applied to the document key (meta().id).
It worth noting that collection will help for number of usage cases like this, however there will still be time when the projector will have to parser large documents and in those cases will still hit this problem
Attachments
Issue Links
| For Gerrit Dashboard: MB-23910 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 85881,1 | MB-23910 - High CPU utilization by the projector (need to optimize N1QL parse/evaluate) Use NewParsedValue() Method | unstable | indexing | Status: ABANDONED | 0 | 0 |
| 85884,2 | MB-23910 - High CPU utilization by the projector (need to optimize N1QL parse/evaluate) Use NewParsedValue() Method | unstable | indexing | Status: MERGED | +2 | +1 |
| 86569,2 | MB-23910 - High CPU utilization by the projector (need to optimize N1QL parse/evaluate) Check if document is JSON | unstable | indexing | Status: MERGED | +2 | +1 |
| 87306,3 | MB-23910 - High CPU utilization by the projector | unstable | indexing | Status: MERGED | +2 | +1 |