Details
-
Epic
-
Resolution: Unresolved
-
 Major
Major
-
None
-
KV: DCP Scalability
-
To Do
Description
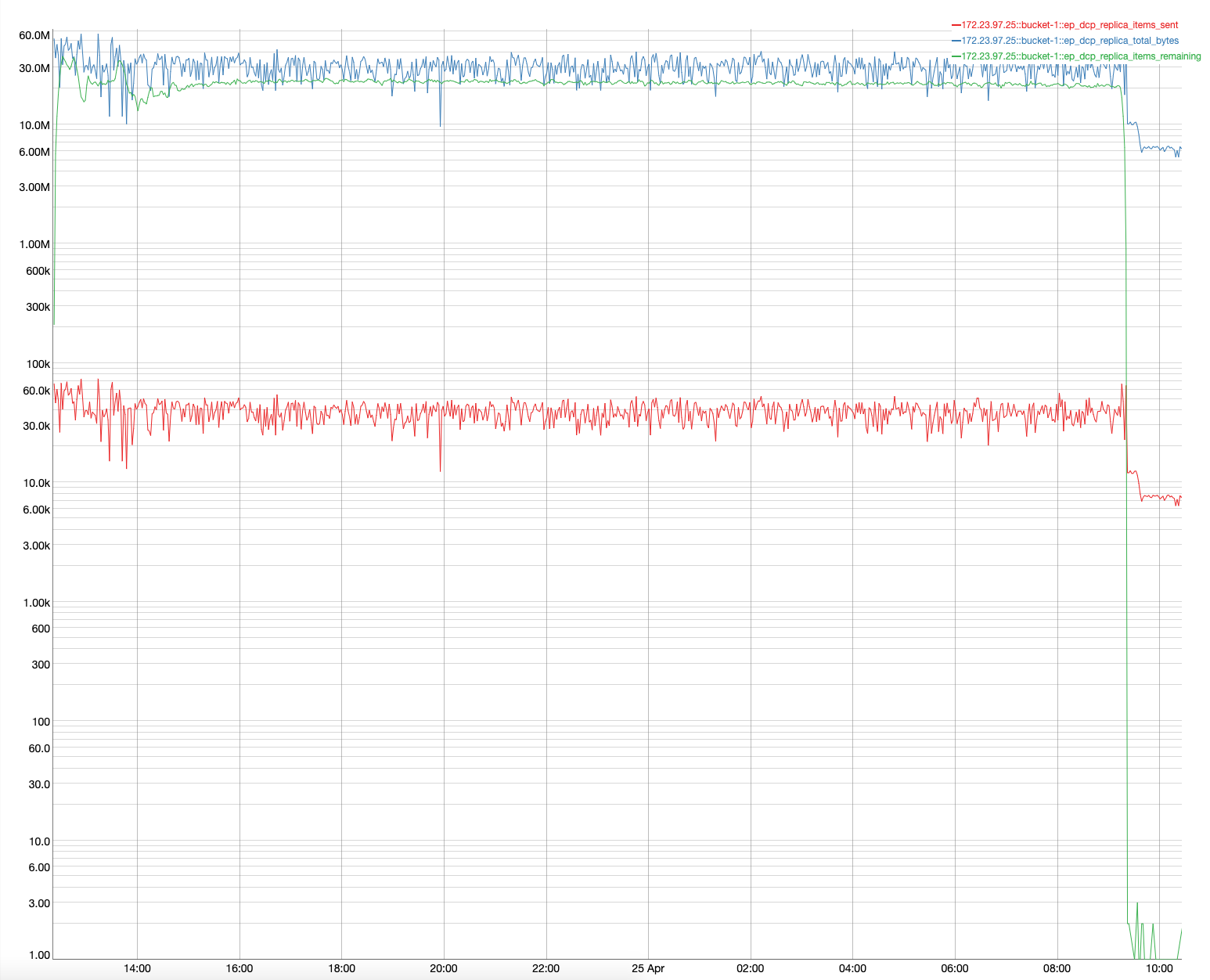
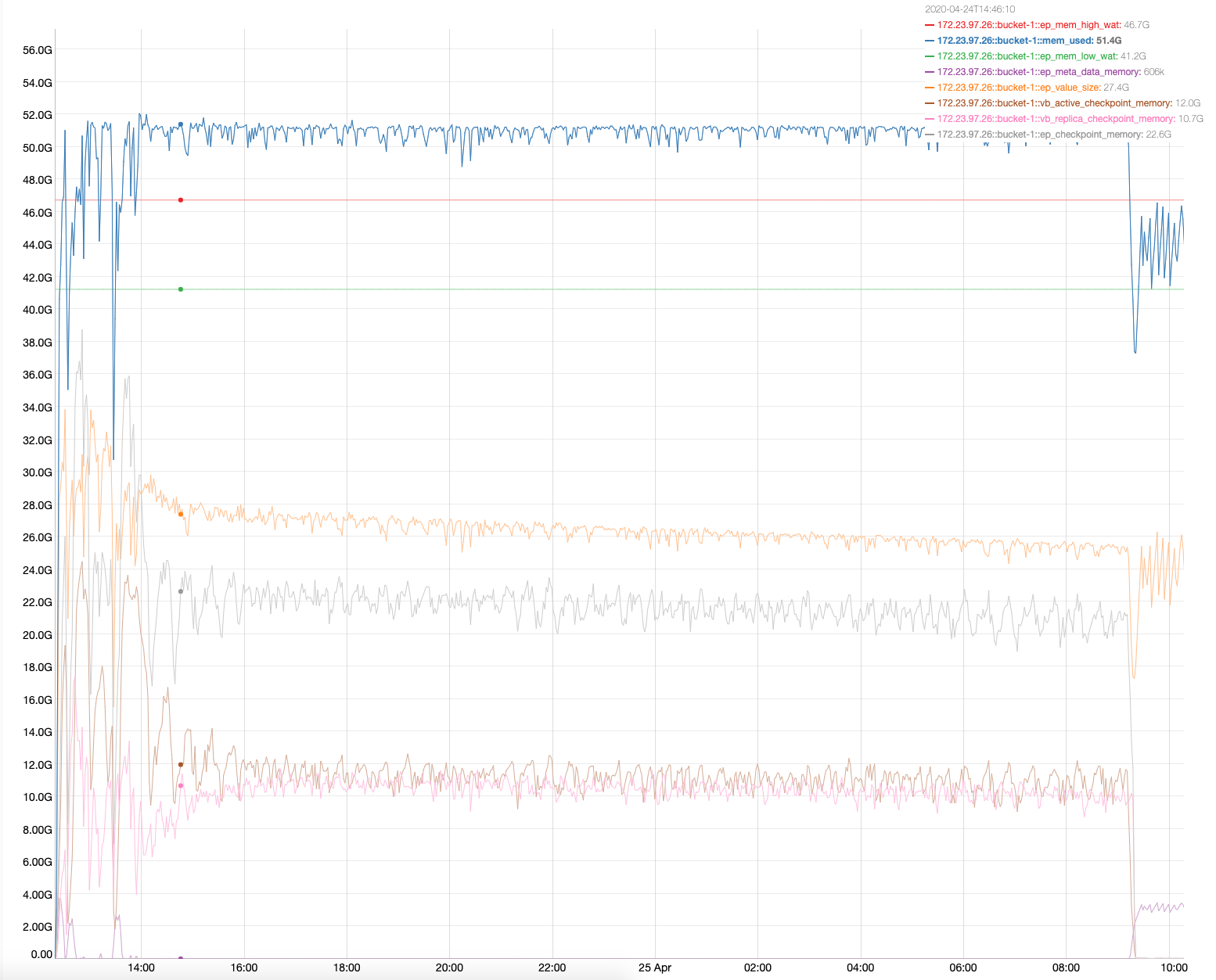
We have observed that DCP throughput per server in a two-node cluster max out at 70K/s and 10K/s on disk backfill. This primarily becomes a bottleneck when the storage engine is faster than DCP. Since replica depends on DCP for replication, overall write throughput of the system is capped by DCP replication throughput.
Attachments

Issue Links
- duplicates
-
-
- Closed
-
- is duplicated by
-
MB-34733 Replication queue limiting magma throughput
-
- Closed
-
- relates to
-
-

- Open
-
-
-
- Closed
-
-
MB-29325 Intra-cluster replication uses only a fraction of network and disk before bottlenecking
-
- Closed
-
- links to
Gerrit Reviews
| For Gerrit Dashboard: MB-36370 | ||||||
|---|---|---|---|---|---|---|
| # | Subject | Branch | Project | Status | CR | V |
| 131939,9 | MB-36370: Trace DCP | master | kv_engine | Status: NEW | 0 | -1 |
| 133206,2 | MB-36370: Add the new DCP "backoff" stats in Connection | master | kv_engine | Status: NEW | -1 | -1 |
| 133499,37 | MB-36370: Add DCP cluster_test perf suite | master | kv_engine | Status: NEW | 0 | 0 |
| 134989,6 | MB-36370: DCP Consumer just increases HT item count at DcpMutation | master | kv_engine | Status: NEW | 0 | -1 |
| 132012,2 | MB-36370: Remove BackfillManager::bytesForceRead | master | kv_engine | Status: MERGED | +2 | +1 |
| 135423,7 | MB-36370: Optimize the cluster_testapp replication proxy | master | kv_engine | Status: MERGED | +2 | +1 |