Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
None
-
Untriaged
-
Unknown
-
Magma: Jan 20 - Feb 2
Description
A 2 node cluster running 1% DGM test abruptly dropped ops rate from 240k writes/sec to 400/s when the active resident is at 27%. The test was in the initial loading phase of 12B docs (loaded 460M). Memory used by magma is around 3G per node.
Logs:
https://uploads.couchbase.com/magma/collectinfo-2020-02-21T092448-ns_1%40172.23.97.25.zip
https://uploads.couchbase.com/magma/collectinfo-2020-02-21T092448-ns_1%40172.23.97.26.zip
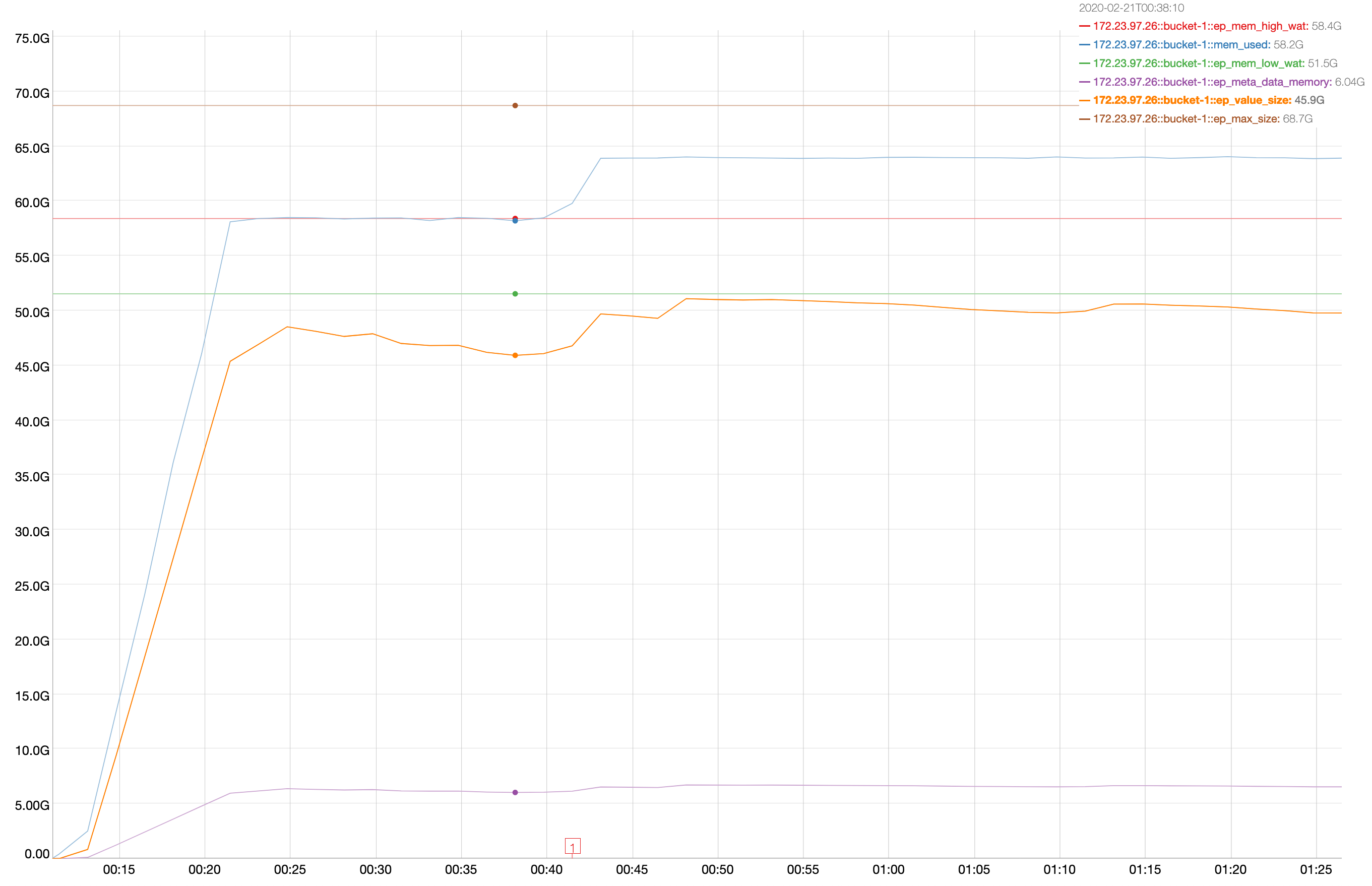
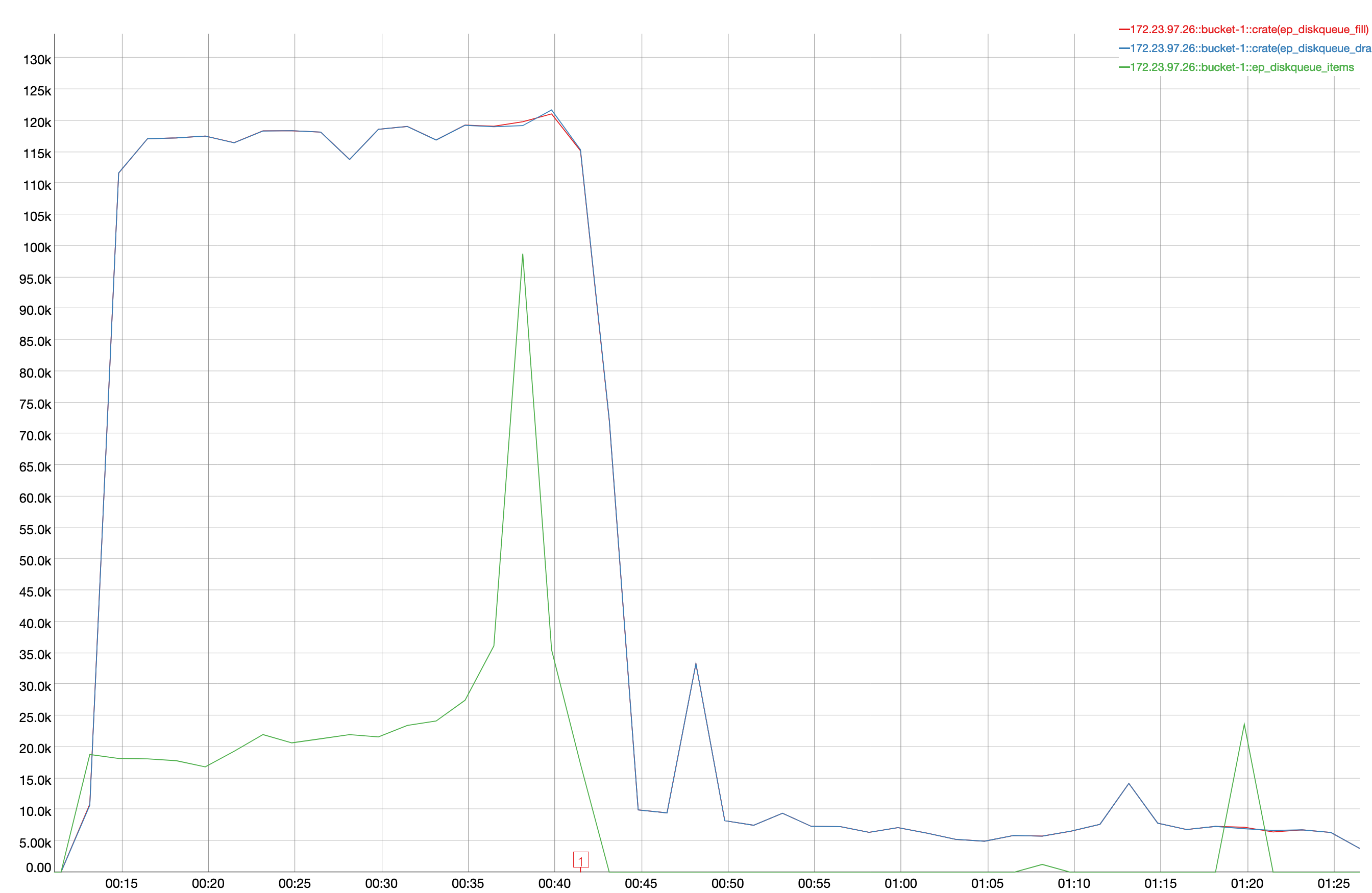
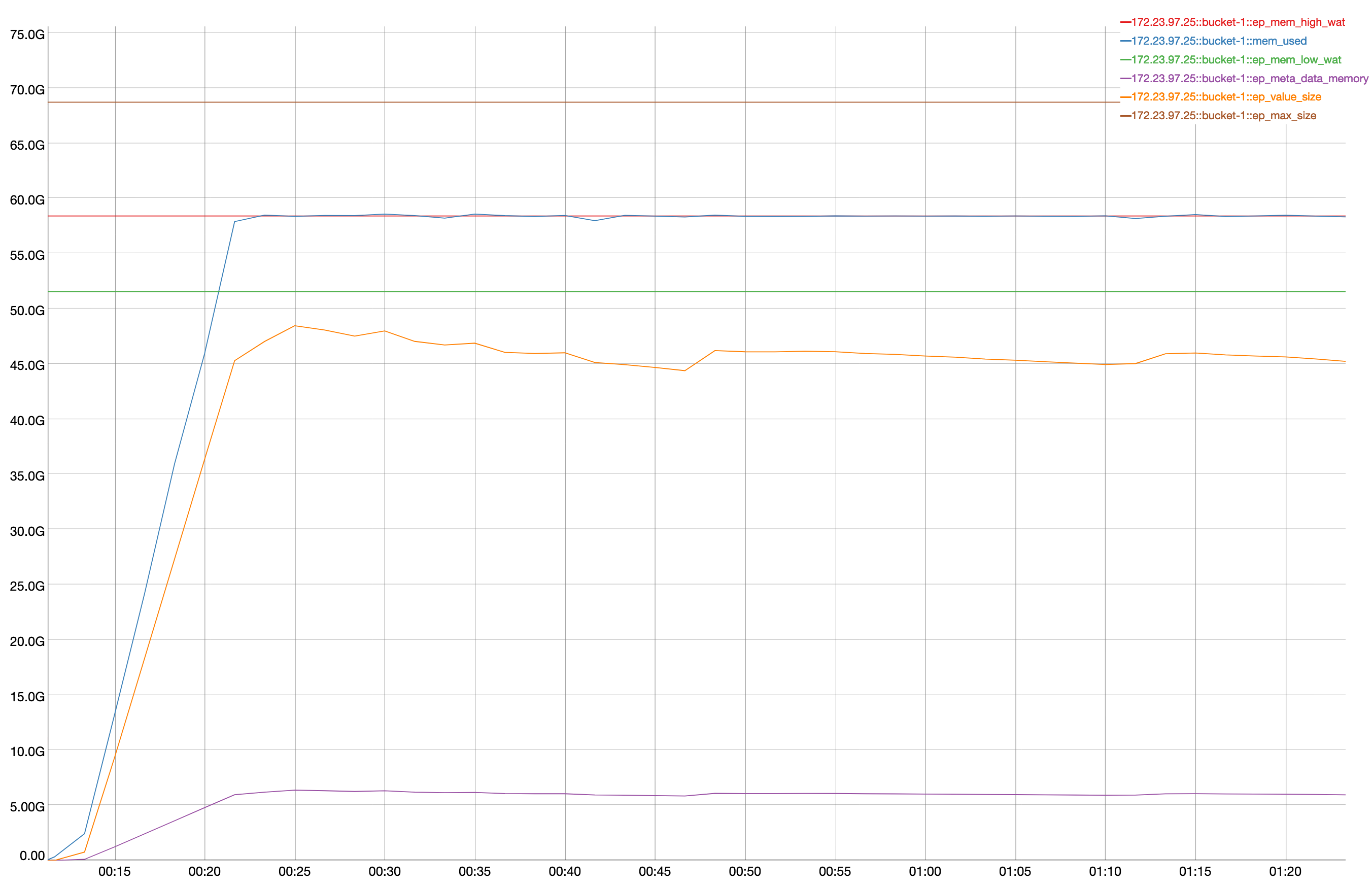
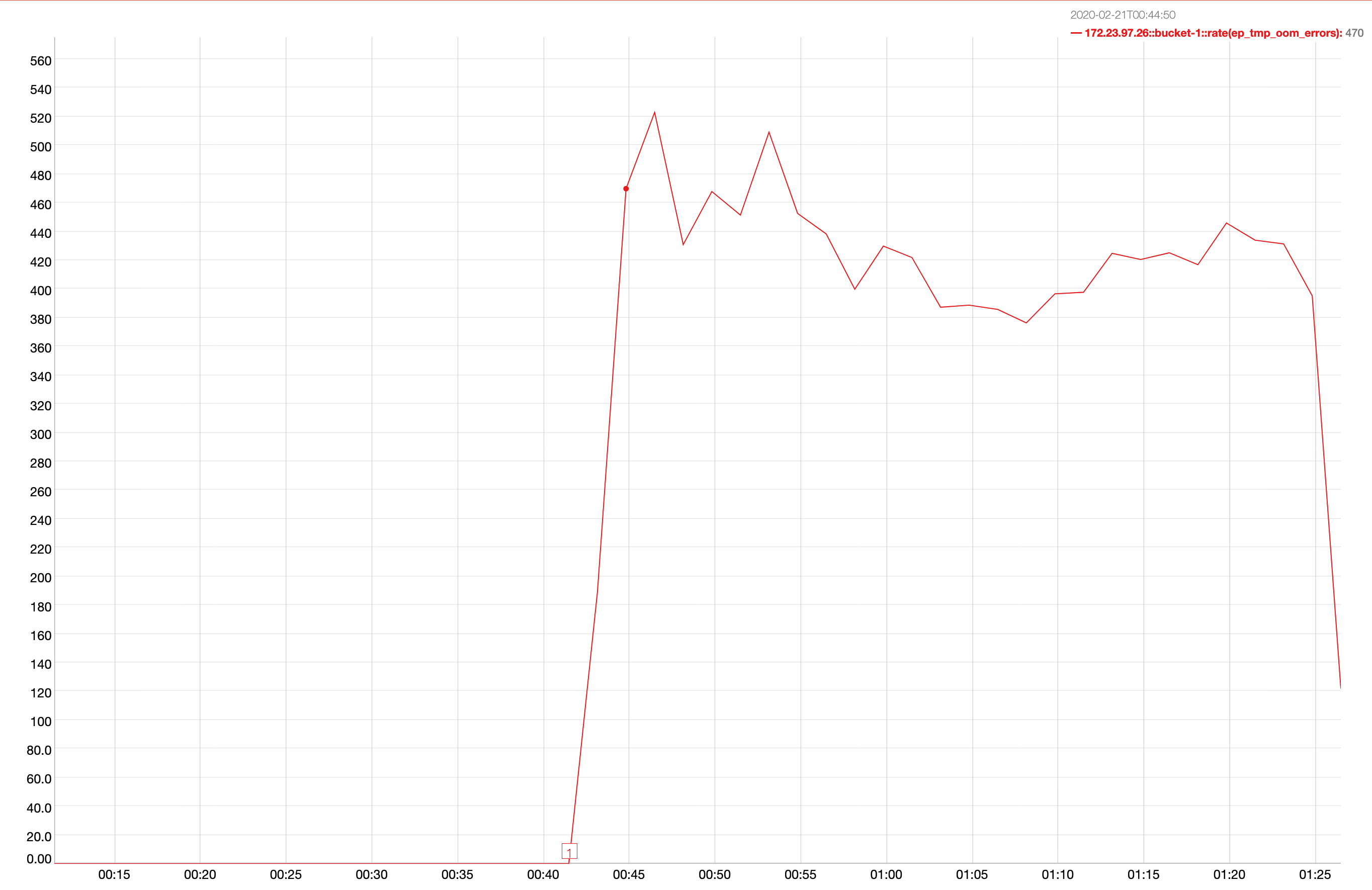
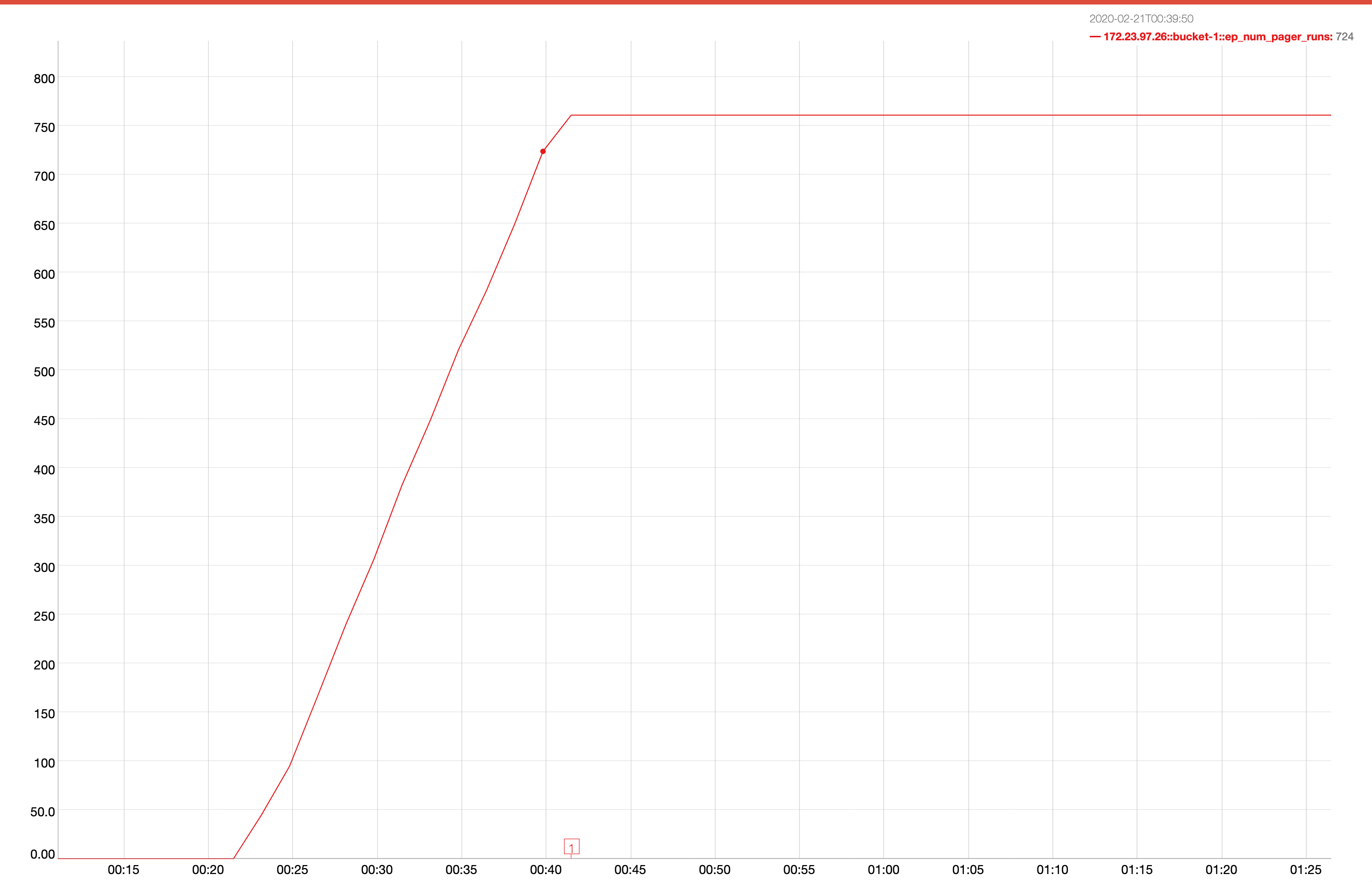
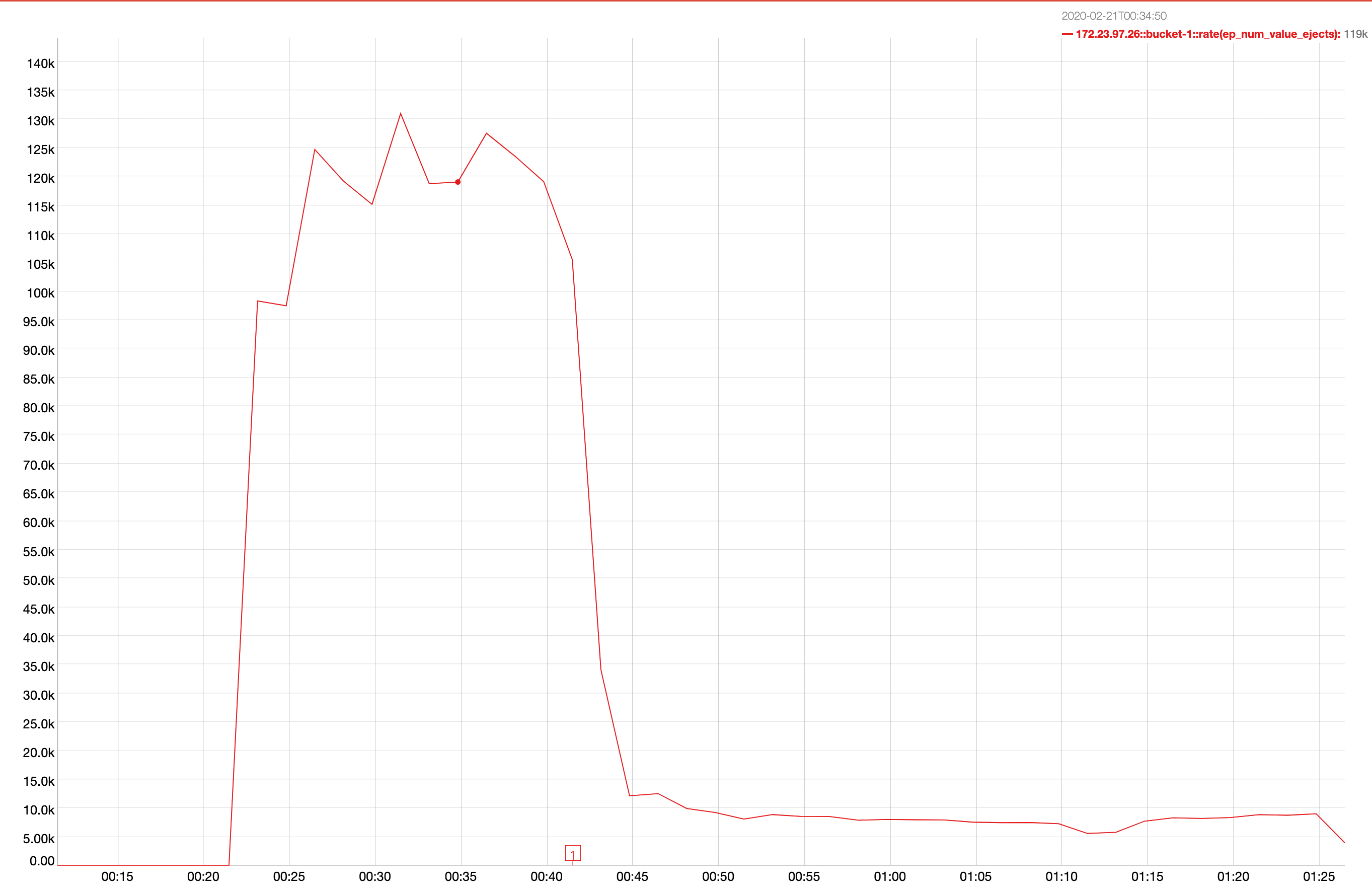
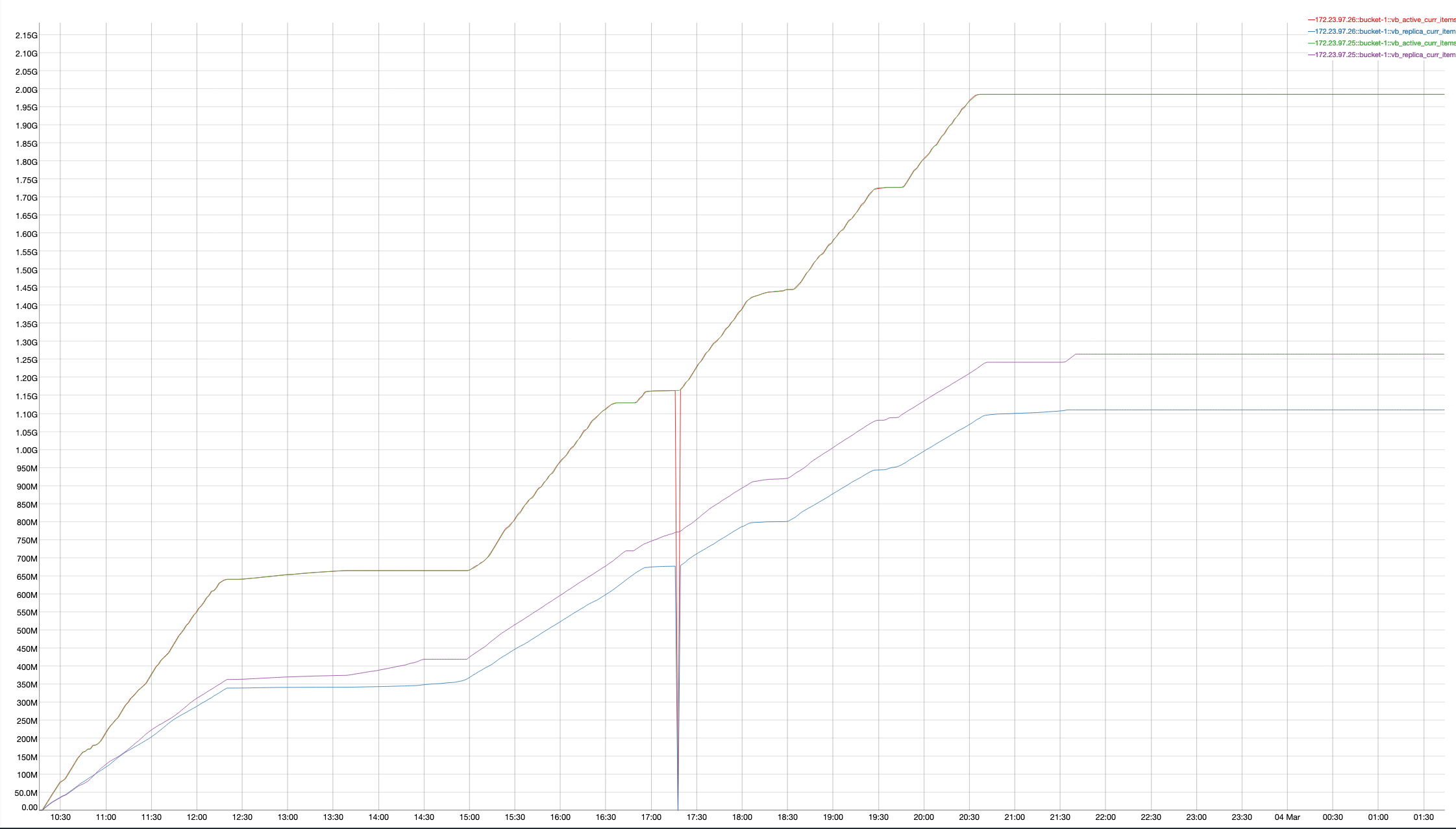
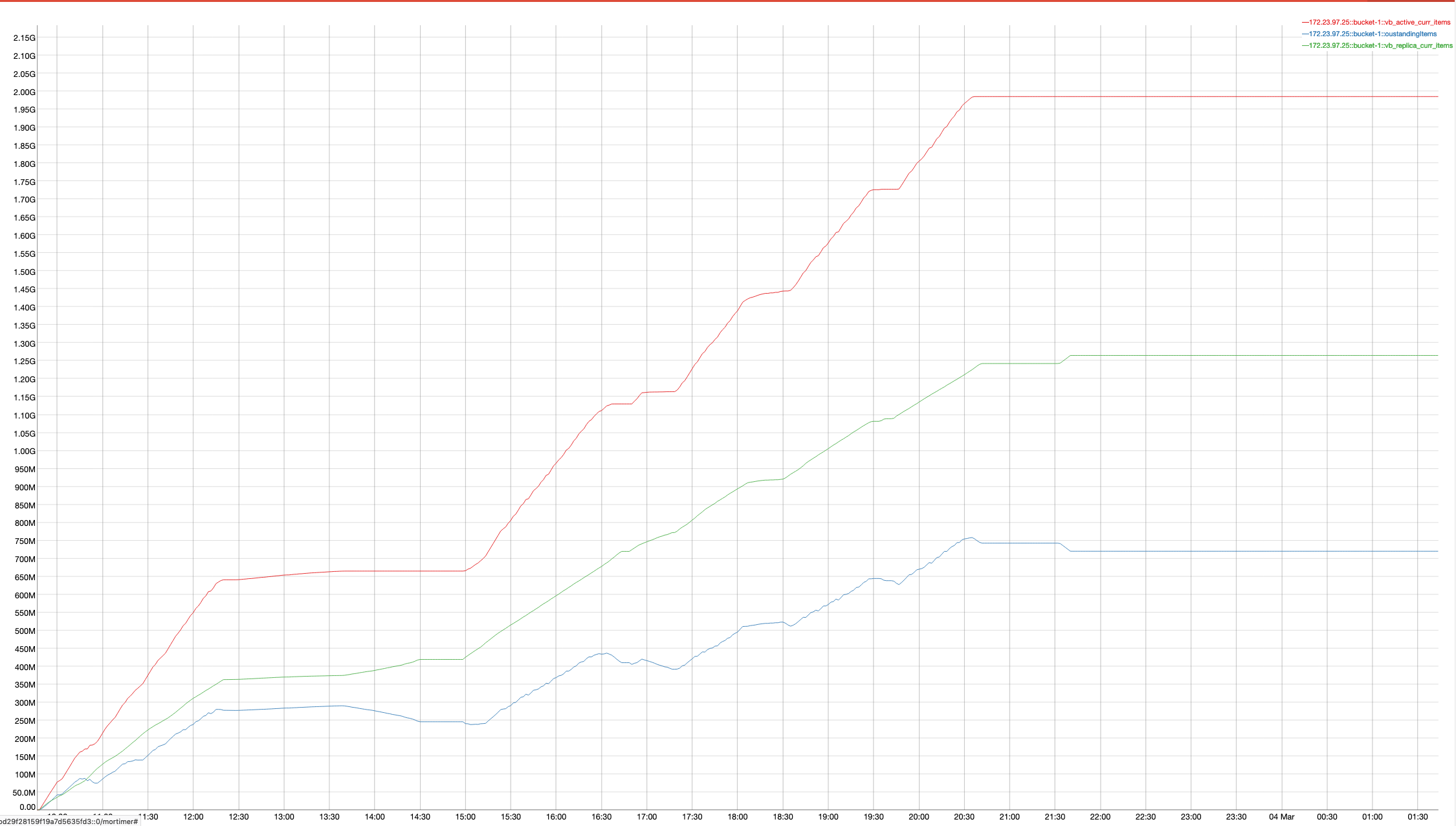
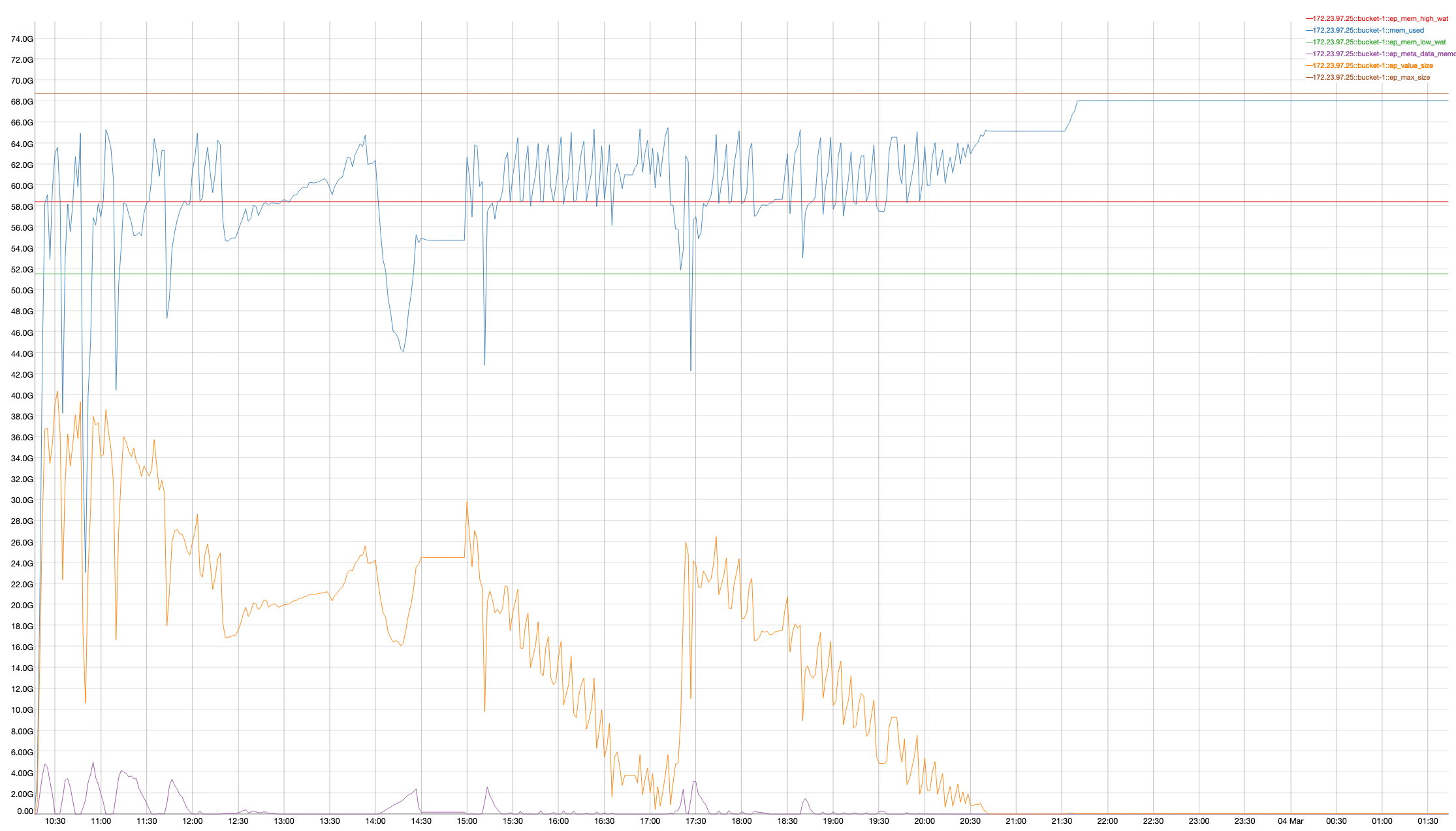
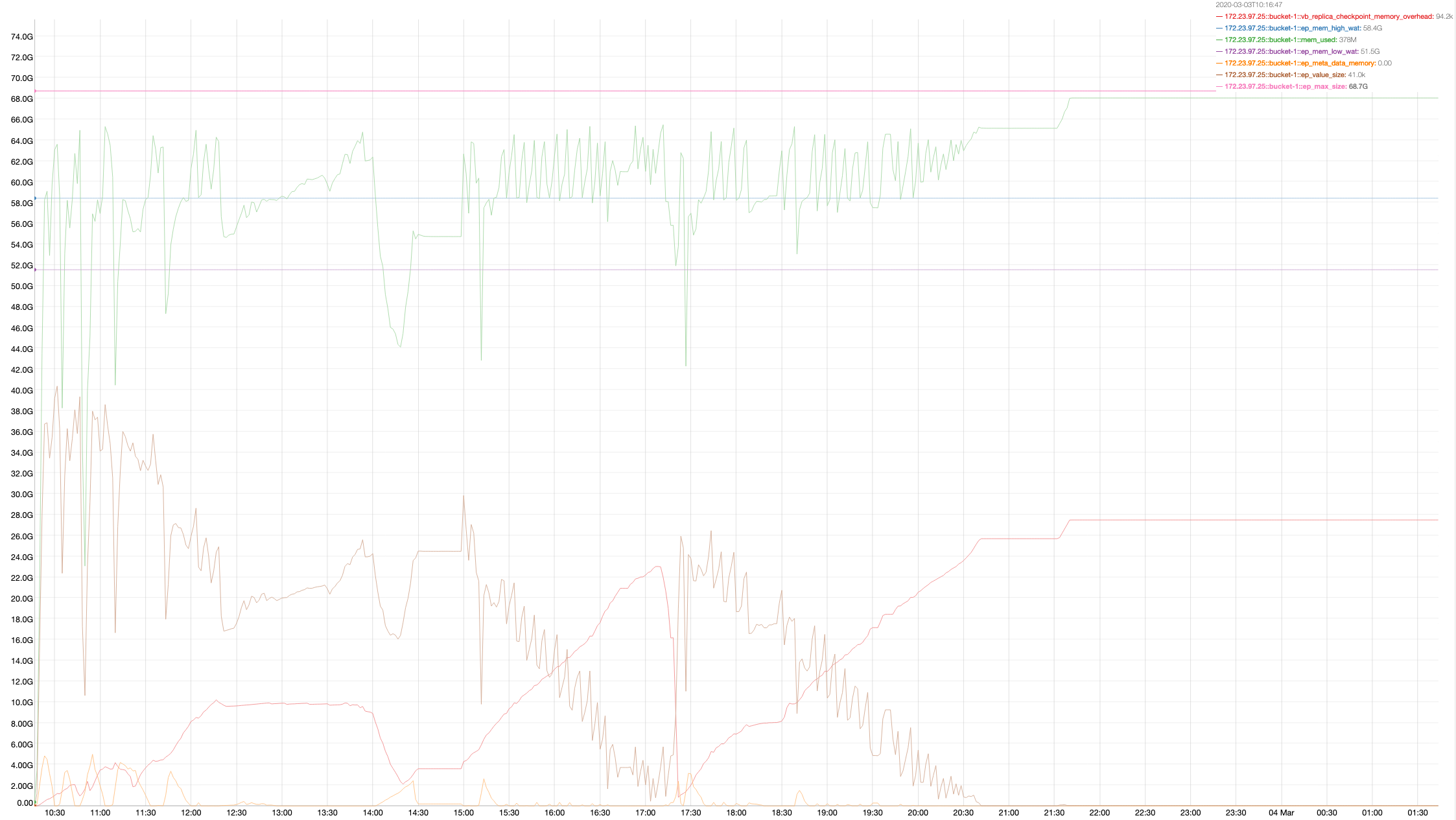
{kind=link}