Details
-
Bug
-
Resolution: Fixed
-
 Critical
Critical
-
Cheshire-Cat
-
Enterprise Edition 7.0.0 build 5060
Windows
-
Untriaged
-
Windows 64-bit
-
-
1
-
Unknown
Description
Build: 7.0.0 - 5060
Scenario:
Adding 2 nodes into the cluster (1 KV and 1 n1ql+index) node.
Cluster has active FTS, 2i, eventing and cbas services running.
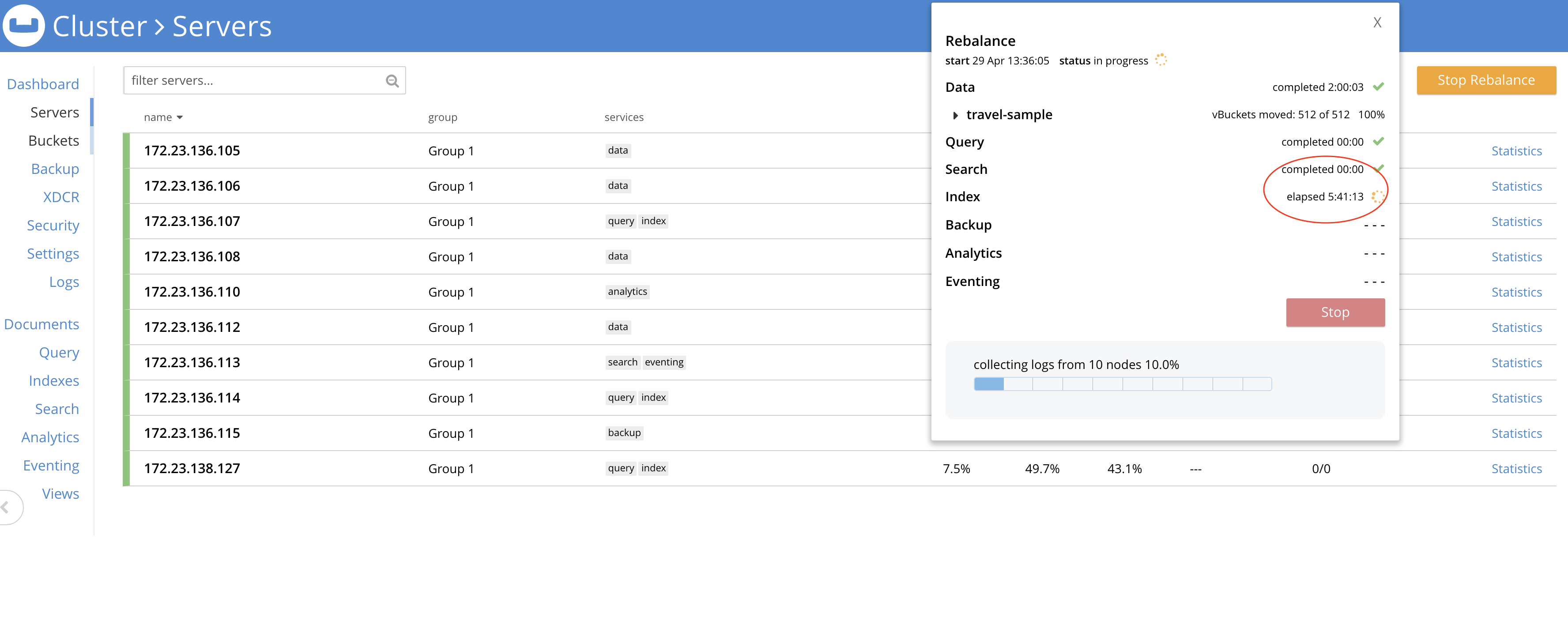
Observing index rebalance step stuck for more than 5 hrs.
Rebalance Operation Id = cb4133936ca1cf441dfb7e7e80b08fd8
+----------------+----------------+-----------------------+----------------+--------------+
|
| Nodes | Services | Version | CPU | Status |
|
+----------------+----------------+-----------------------+----------------+--------------+
|
| 172.23.136.114 | index, n1ql | 7.0.0-5017-enterprise | 16.2759689664 | Cluster node |
|
| 172.23.136.106 | kv | 7.0.0-5017-enterprise | 96.3590072138 | Cluster node |
|
| 172.23.136.107 | kv | 7.0.0-5017-enterprise | 95.904451103 | Cluster node |
|
| 172.23.136.108 | index, n1ql | 7.0.0-5017-enterprise | 6.25161456988 | Cluster node |
|
| 172.23.136.115 | backup | 7.0.0-5017-enterprise | 0.247504125069 | Cluster node |
|
| 172.23.136.113 | eventing, fts | 7.0.0-5017-enterprise | 48.0959898431 | Cluster node |
|
| 172.23.136.110 | kv | 7.0.0-5017-enterprise | 82.6015216793 | Cluster node |
|
| 172.23.136.105 | kv | 7.0.0-5017-enterprise | 97.6586680867 | Cluster node |
|
| 172.23.136.112 | ['kv'] | | | <--- IN --- |
|
| 172.23.138.127 | ['n1ql,index'] | | | <--- IN --- |
|
+----------------+----------------+-----------------------+----------------+--------------+
|
Attachments
Issue Links
- relates to
-
-

- Closed
-