Details
-
Bug
-
Resolution: Duplicate
-
 Blocker
Blocker
-
Cheshire-Cat
-
6.6.2-9588 -> 7.0.0-5275
-
Untriaged
-
Centos 64-bit
-
1
-
Yes
Description
Script to Repro
1. Run the following 6.6.2 longevity test for 3-4 days. We will have 27 node cluster at the end of it.
./sequoia -client 172.23.96.162:2375 -provider file:centos_third_cluster.yml -test tests/integration/test_allFeatures_madhatter_durability.yml -scope tests/integration/scope_Xattrs_Madhatter.yml -scale 3 -repeat 0 -log_level 0 -version 6.6.2-9588 -skip_setup=false -skip_test=false -skip_teardown=true -skip_cleanup=false -continue=false -collect_on_error=false -stop_on_error=false -duration=604800 -show_topology=true
|
2. Run the script create_drop_1.sh![]() on 6.6.2 nodes on the cluster. And this was run on the 7.0.0 nodes as well that will be brought into the cluster using swap rebalance for upgrade
on 6.6.2 nodes on the cluster. And this was run on the 7.0.0 nodes as well that will be brought into the cluster using swap rebalance for upgrade
3. Swap rebalance 6(1 of each service) 6.6.2 nodes with 7.0.0 nodes.
4. Graceful failover 6 node (1 of each service), upgrade, do a recovery and start rebalance.
5. Graceful failover 6 node (1 of each service), upgrade, do a recovery and start rebalance. After repeated retry of the failed rebalance(see MB-46778), this rebalance succeeded.
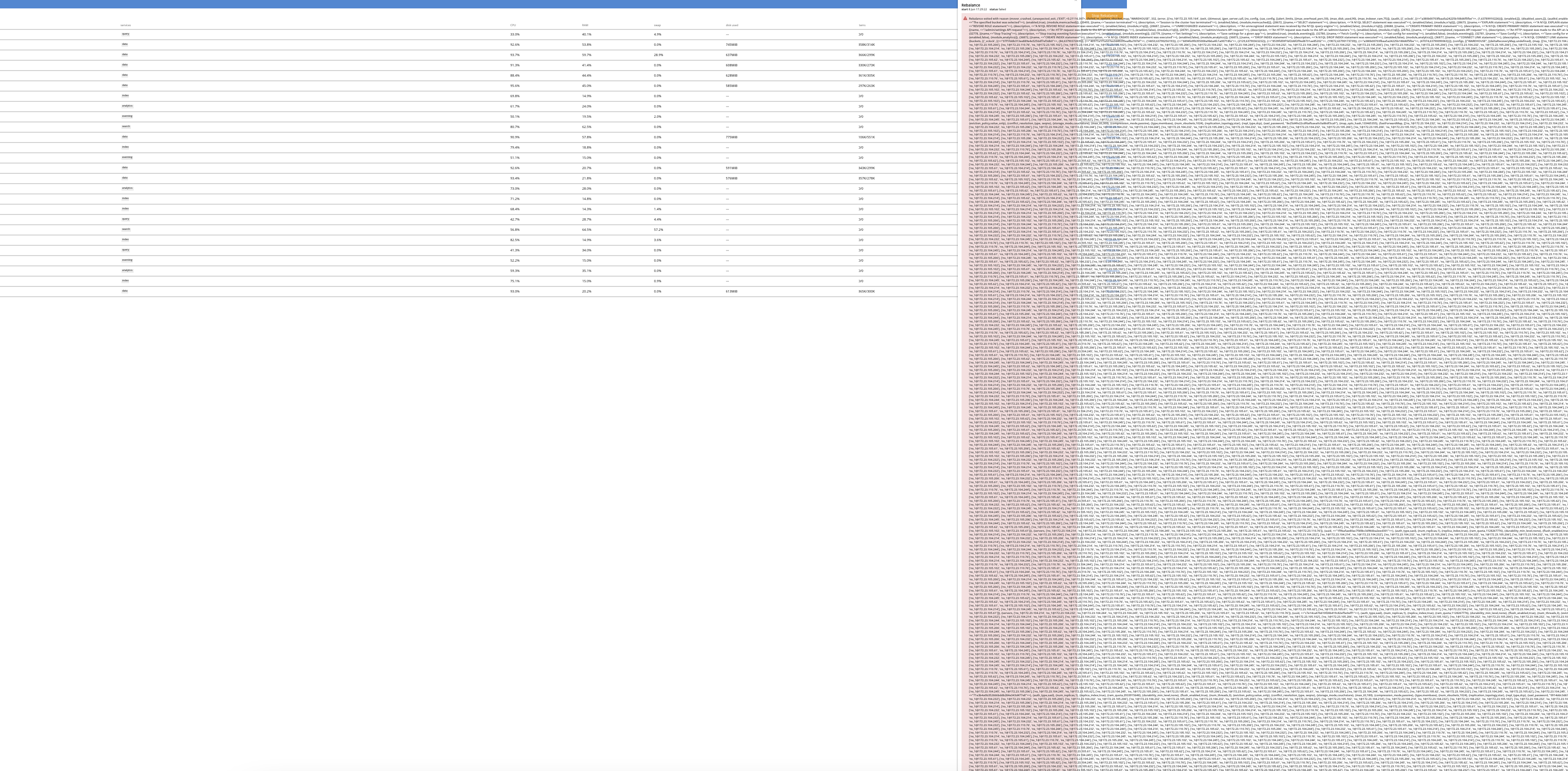
6. Now tried to a graceful failover a kv node(172.23.105.206) which fails as shown below.
Failover of the indexer node
[user:info,2021-06-08T00:40:51.919-07:00,ns_1@172.23.110.76:<0.26472.4>:ns_orchestrator:idle:718]Starting graceful failover of nodes ['ns_1@172.23.105.206']. Operation Id = b34faa3bb10a3c6cdbda493098c828d9
|
Failure
"completionMessage": "Graceful failover exited with reason {mover_crashed,\n {unexpected_exit,\n {'EXIT',<0.17744.617>,\n {failed_to_update_vbucket_map,\n \"WAREHOUSE\",369,\n {error,\n [{'ns_1@172.23.106.207',\n {exit,\n {{nodedown,'ns_1@172.23.106.207'},\n {gen_server,call,\n [{ns_config_rep,\n 'ns_1@172.23.106.207'},\n synchronize_everything,\n infinity]}}}}]}}}}}."
|
See rebalanceReport (1).json![]() for more details. I am fairly certain this is a dup of
for more details. I am fairly certain this is a dup of MB-46778. However, just don't want to mess up the timeline of that bug in case it turns out to be a different one.
cbcollect_info attached. This was not seen on last system test upgrade we had from 6.6.2-9588 -> 7.0.0-5226
See also MB-46783.
Attachments
Issue Links
- duplicates
-
-

- Closed
-