Details
-
Bug
-
Resolution: Duplicate
-
 Critical
Critical
-
None
-
7.1.0
-
7.0.3-7031 -> 7.1.0-2335
-
Untriaged
-
Centos 64-bit
-
1
-
No
Description
Script to Repro
1. Run CC longevity on 7.0.3 for 2-3 days
./sequoia -client 172.23.104.254:2375 -provider file:centos_second_cluster.yml -test tests/integration/cheshirecat/test_cheshirecat_kv_gsi_coll_xdcr_backup_sgw_fts_itemct_txns_eventing_cbas_scale3.yml -scope tests/integration/cheshirecat/scope_cheshirecat_with_backup.yml -scale 3 -repeat 0 -log_level 0 -version 7.0.3-7031 -skip_setup=false -skip_test=false -skip_teardown=true -skip_cleanup=false -continue=false -collect_on_error=false -stop_on_error=false -duration=604800 -show_topology=true
|
2. Change the encryption level to strict.
3. Add 2 kv nodes and 2 indexing nodes, Remove 2 kv and 2 indexing nodes and do swap rebalance. This failed in indexing. See MB-51096.
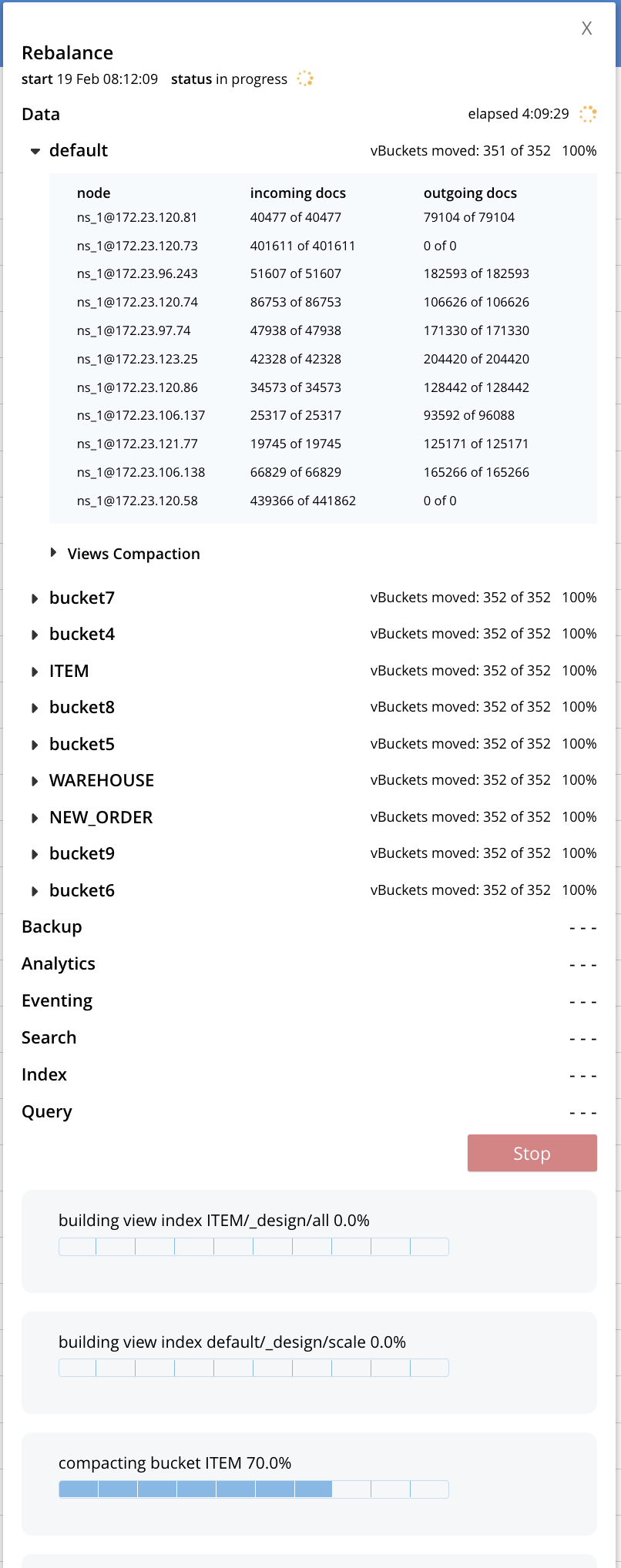
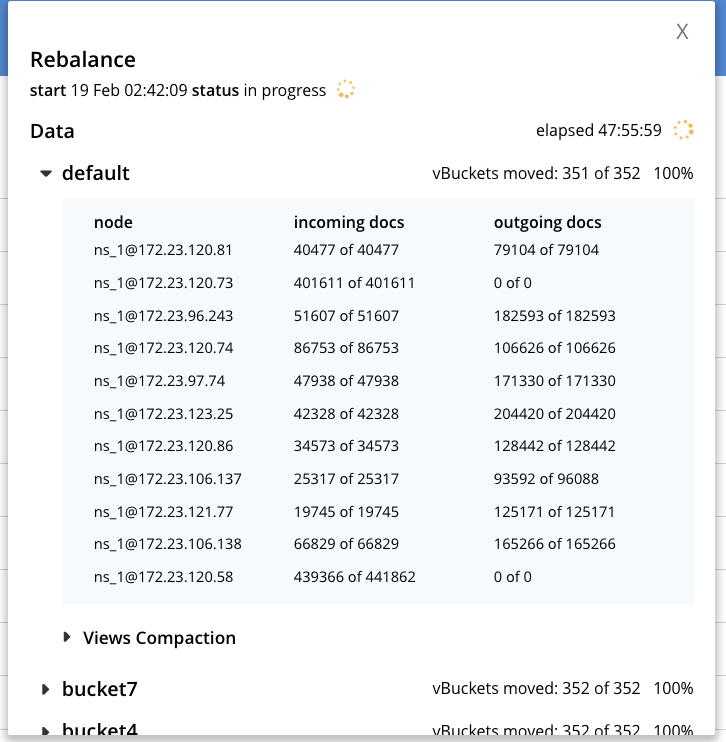
4. Retried failed rebalance. This has been stuck for over 48 hours.
After 4 hours : 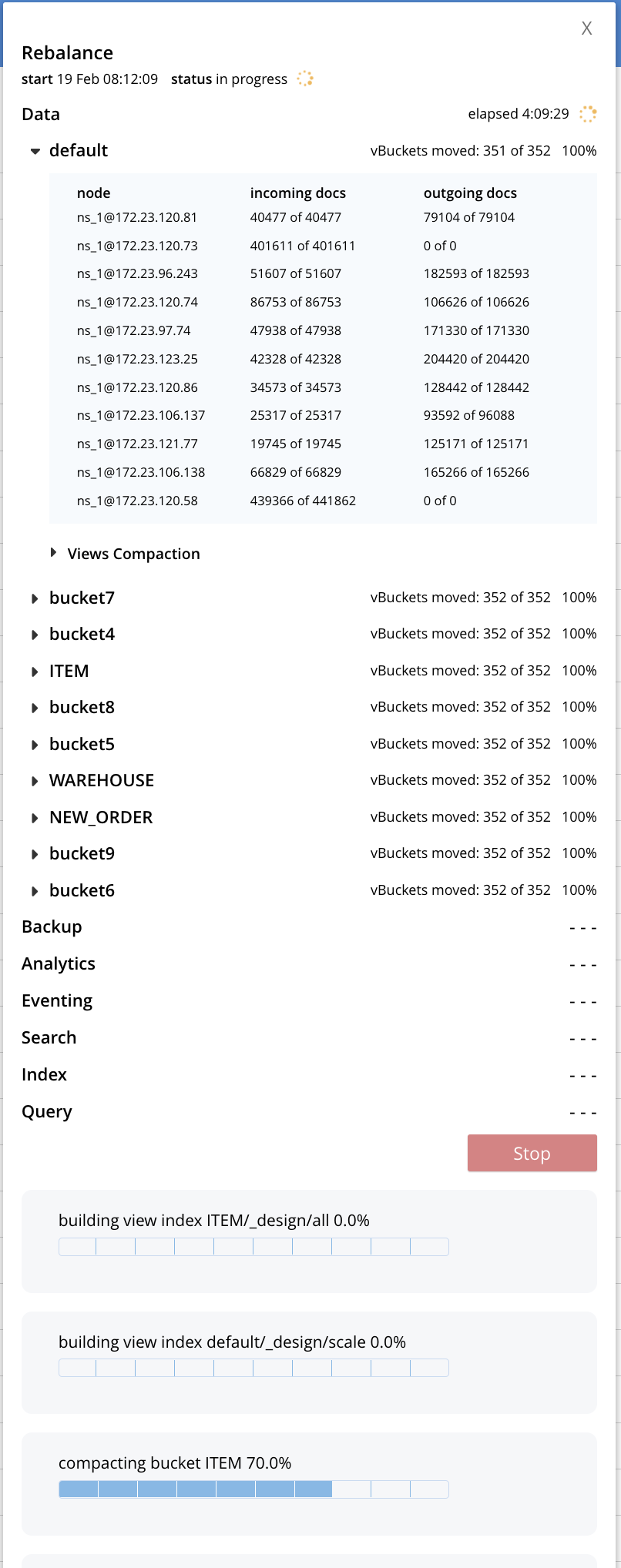
After 48 hours : 
When we look at the node 172.23.120.58 we see compactions being stuck.
172.23.120.58
[root@localhost logs]# cat /opt/couchbase/VERSION.txt
|
7.0.3-7031
|
[root@localhost logs]#
|
[root@localhost logs]# zgrep 'awaiting completion' memcached.log.0000* | wc -l
|
504949
|
It does looks like one of the side effects of MB-50988. We also have MB-51027 which is due to the same bug.
I have marked it as No for regression but here are more details.
Run 1
7.0.3-7031 -> 7.1.0-2235.
Started online upgrade with swap rebalance with (2 Kv + 2 index nodes). Kv rebalance completed and indexing got stuck. See MB-50832. However there was no work around for that bug. So, we had to abandon the upgrade.
Run 2(Current run)
7.0.3-7031 -> 7.1.0-2335
Started online upgrade with swap rebalance with (2 Kv + 2 index nodes). Kv rebalance completed and indexing rebalance failed. See MB-51096. Retried failed rebalance which got stuck, hence this bug.
cbcollect_info attached.