Details
-
Bug
-
Resolution: Not a Bug
-
 Major
Major
-
7.6.0
-
7.6.0-1606
-
Untriaged
-
Centos 64-bit
-
-
0
-
No
Description
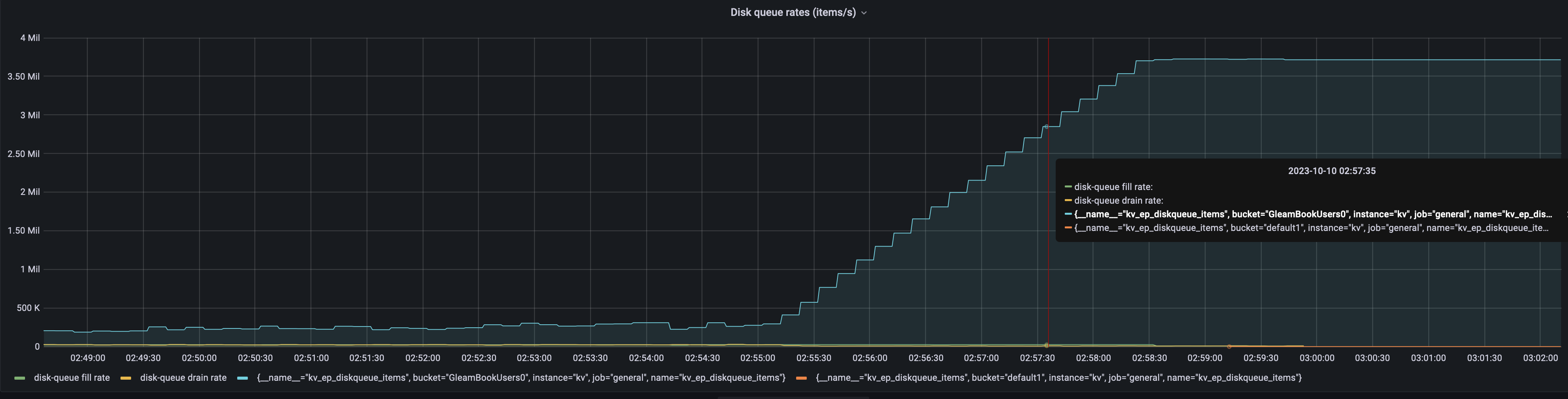
This MB is a clone from MB-59037 as it was noted that a bucket took long to delete (for reconfiguration), and the same problem occurred on all but 172.23.107.232.
From the memcached logs for example on 172.23.107.97 the following grep in memcached.log hightlights the slow flusher "stop", 194s.
> grep -e "stop flusher" -e Flusher::wait memcached.log
|
2023-10-09T18:59:53.131262-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:0
|
2023-10-09T19:03:07.145242-07:00 INFO (GleamBookUsers0) Flusher::wait: had to wait 194 s for shutdown
|
2023-10-09T19:03:07.145254-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:1
|
2023-10-09T19:03:07.146782-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:2
|
2023-10-09T19:03:07.147955-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:3
|
2023-10-09T19:03:07.149108-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:4
|
2023-10-09T19:03:07.150247-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:5
|
2023-10-09T19:03:09.408951-07:00 INFO (GleamBookUsers0) Flusher::wait: had to wait 2259 ms for shutdown
|
2023-10-09T19:03:09.408970-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:6
|
2023-10-09T19:03:09.862978-07:00 INFO (GleamBookUsers0) Flusher::wait: had to wait 454 ms for shutdown
|
2023-10-09T19:03:09.862993-07:00 INFO (GleamBookUsers0) Attempting to stop flusher:7
|
The flusher in that instance reported it was running for 189s
2023-10-09T19:03:07.141661-07:00 WARNING (GleamBookUsers0) Slow runtime for 'Running a flusher loop: flusher 0' on thread WriterPool746: 189 s
|
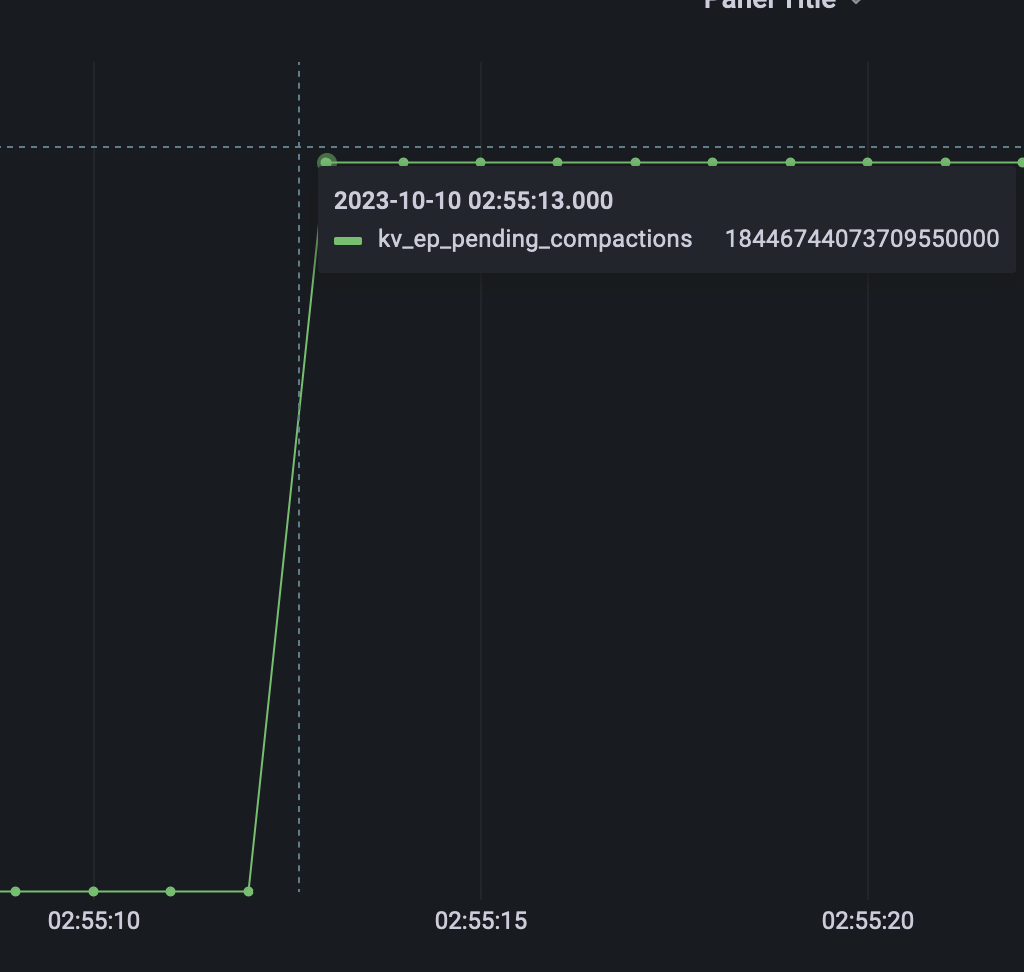
It's unclear where the time was spent, but suspect it could of been inside magma?
Original MB description below, unclear if these steps will always reproduce the slow shutdown.
Steps To Recreate:
- Create a 4 node cluster.
- Create a couchstore bucket(replicas=1, ram_quota =10 GiB per node, bucket_eviction_policy=fullEviction, bucket-name=GleamBookUsers0)
- Create 50 non default collections
- Load 50000000 docs of size 512 bytes in each of the newly created non default collections
- Change storage mode from couchstore to magma
- Start doc:ops(update:read)
- Trigger a swap rebalance(one node coming in one going out)
- Swap rebalance was successfull
- Trigger graceful failover fullrecovery rebalance (failed over node 172.23.107.220) while data loading is going on
- Graceful failover+fullrecovery was successfull
- Trigger hard failover + fullrecovery+ rebalance (failed over node 172.23.107.97) while data loading is going on
- Trigger hard failover + fullrecovery+ rebalance (failed over node 172.23.107.232) while data loading is going on
- Update maxTTL value of VolumeCollection0 and VolumeCollection1
- Delete one collection(VolumeCollection 10)
- Create a collection(with name VolumeCollection10) with history=true
- Stop rebalance and create a new bucket( with historyRetentionCollectionDefault=true -d historyRetentionBytes=8446744073709551615 -d historyRetentionSeconds=3600)
- Update num replicas = 2 , durability=majority and bucket priority to high for bucket GleamBookUsers0
- Start rebalance
- Rebalance exited with reason {pre_rebalance_janitor_run_failed, "GleamBookUsers0", {error,wait_for_memcached_failed,
Restarted rebalance multiple times but it was failing always
Rebalance Failute:
Rebalance exited with reason {pre_rebalance_janitor_run_failed,
|
"GleamBookUsers0",
|
{error,wait_for_memcached_failed,
|
['ns_1@172.23.107.220',
|
'ns_1@172.23.107.239',
|
'ns_1@172.23.107.97']}}.
|
Rebalance Operation Id = 0d32f3032d8813abee3b8aca0cc87262
|
QE-TEST:
guides/gradlew --refresh-dependencies testrunner -P jython=/opt/jython/bin/jython -P 'args=-i /tmp/temp_vol.ini bucket_storage=couchstore,bucket_eviction_policy=fullEviction,rerun=False -t aGoodDoctor.Hospital.Murphy.StorageMigrationTestHappyPath,nodes_init=4,graceful=True,skip_cleanup=True,num_items=50000000,num_buckets=1,bucket_names=GleamBook,doc_size=512,bucket_type=membase,bucket_eviction_policy=valueOnly,iterations=5,batch_size=1000,sdk_timeout=60,log_level=debug,infra_log_level=debug,rerun=False,skip_cleanup=True,key_size=22,assert_crashes_on_load=True,num_collections=50,maxttl=10,num_indexes=0,pc=10,indexer_mem_quota=0,index_nodes=0,cbas_nodes=0,fts_nodes=0,ops_rate=100000,ramQuota=10240,doc_ops=create:update:delete:read,mutation_perc=100,rebl_ops_rate=50000,key_type=RandomKey,revert_migration=True'
|
Attachments
Issue Links
- Clones
-
-

- Closed
-