Details
-
Bug
-
Resolution: Fixed
-
 Major
Major
-
6.5.0
-
Untriaged
-
Yes
-
KV-Engine Mad-Hatter GA, KV Sprint 2020-January
Description
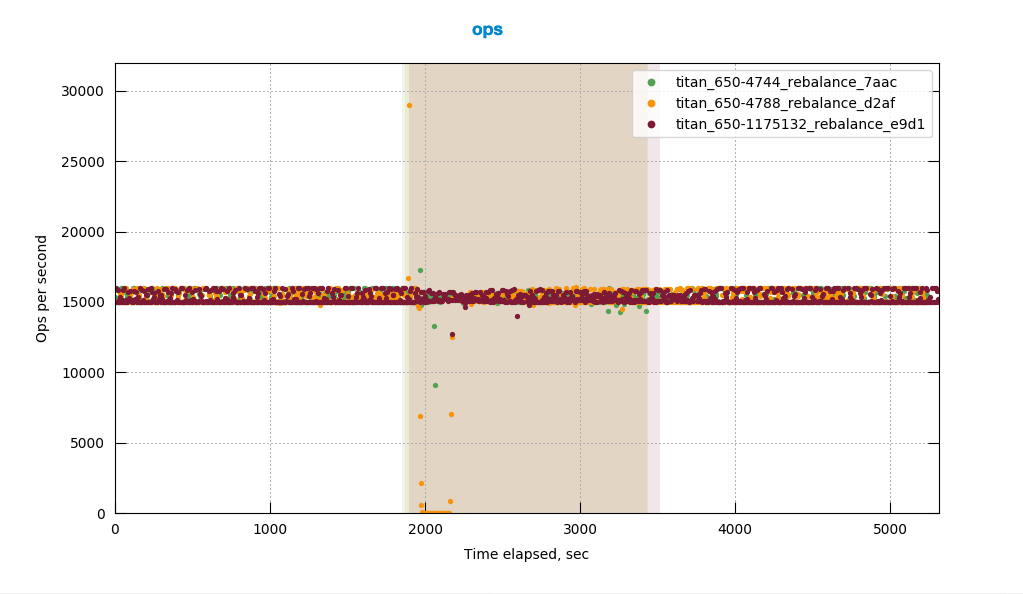
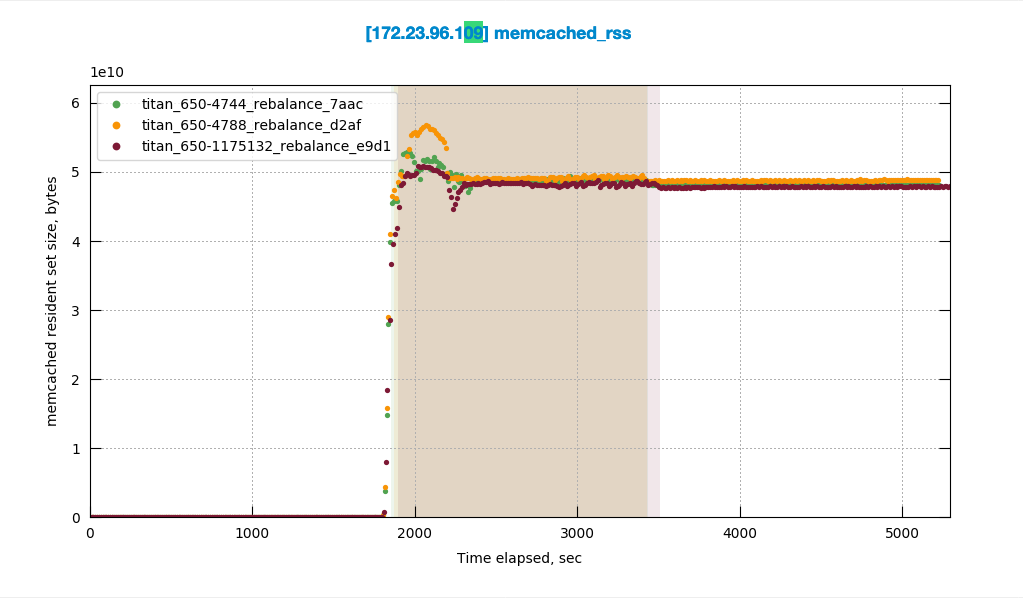
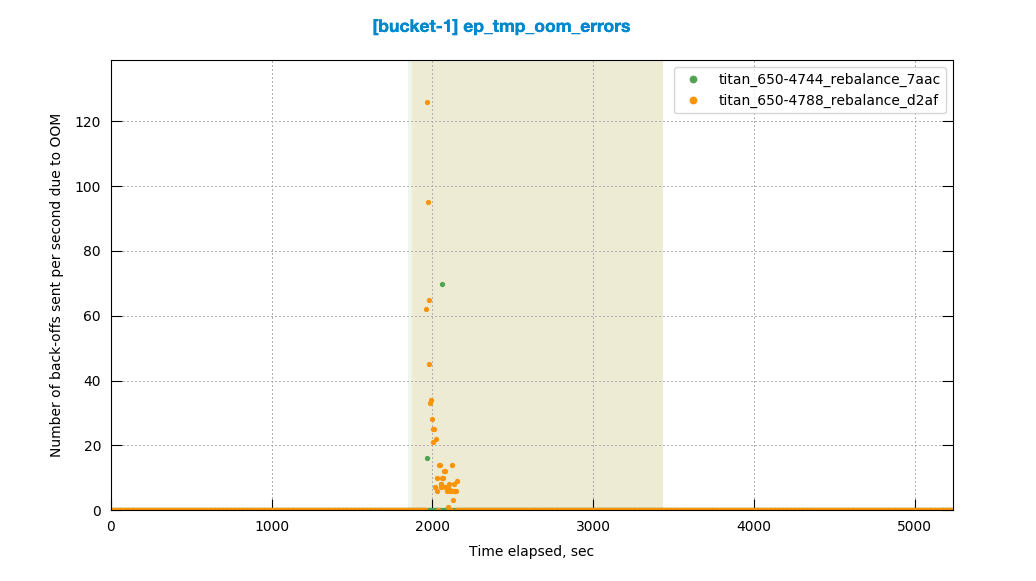
I noticed this in the most recent 9->9 swap rebalance test against 6.5.0-4788: http://cbmonitor.sc.couchbase.com/reports/html/?snapshot=titan_650-4788_rebalance_d2af#19046bfb651c6e0796fef70b7b4a833b.
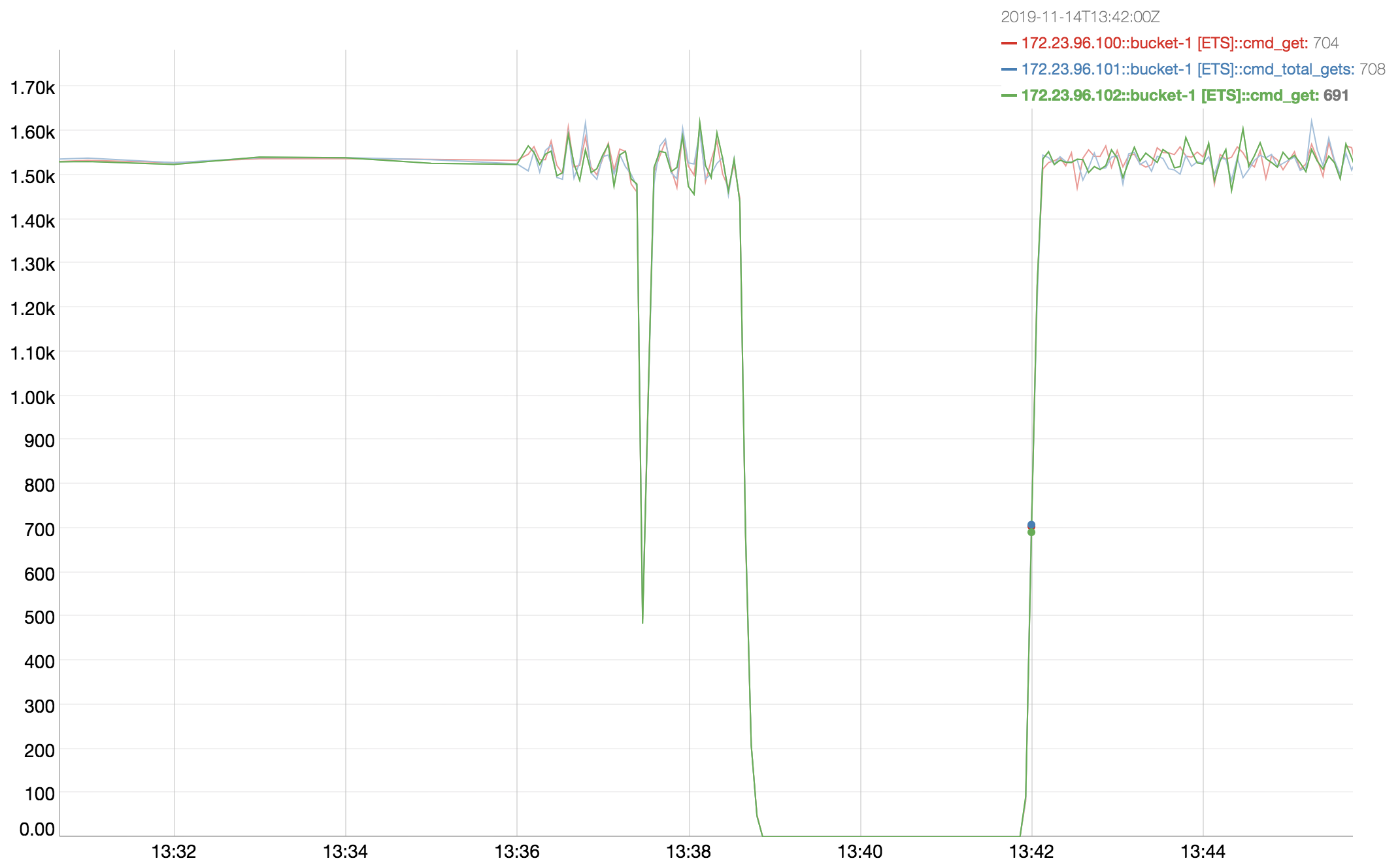
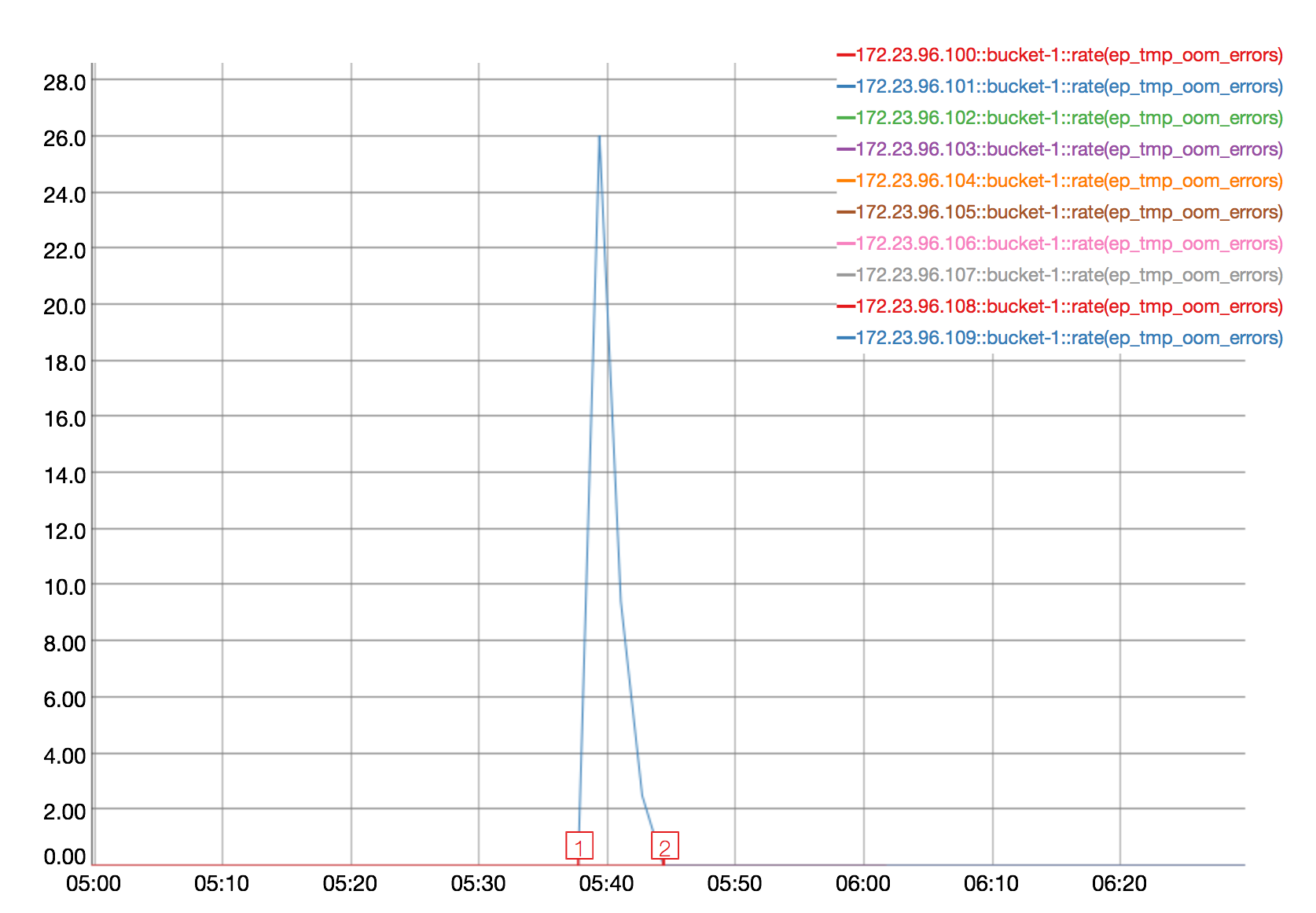
I downloaded some of the logs and looked at mortimer and indeed across the cluster the ops go to zero from around 5:38:52 to 5:41:52:
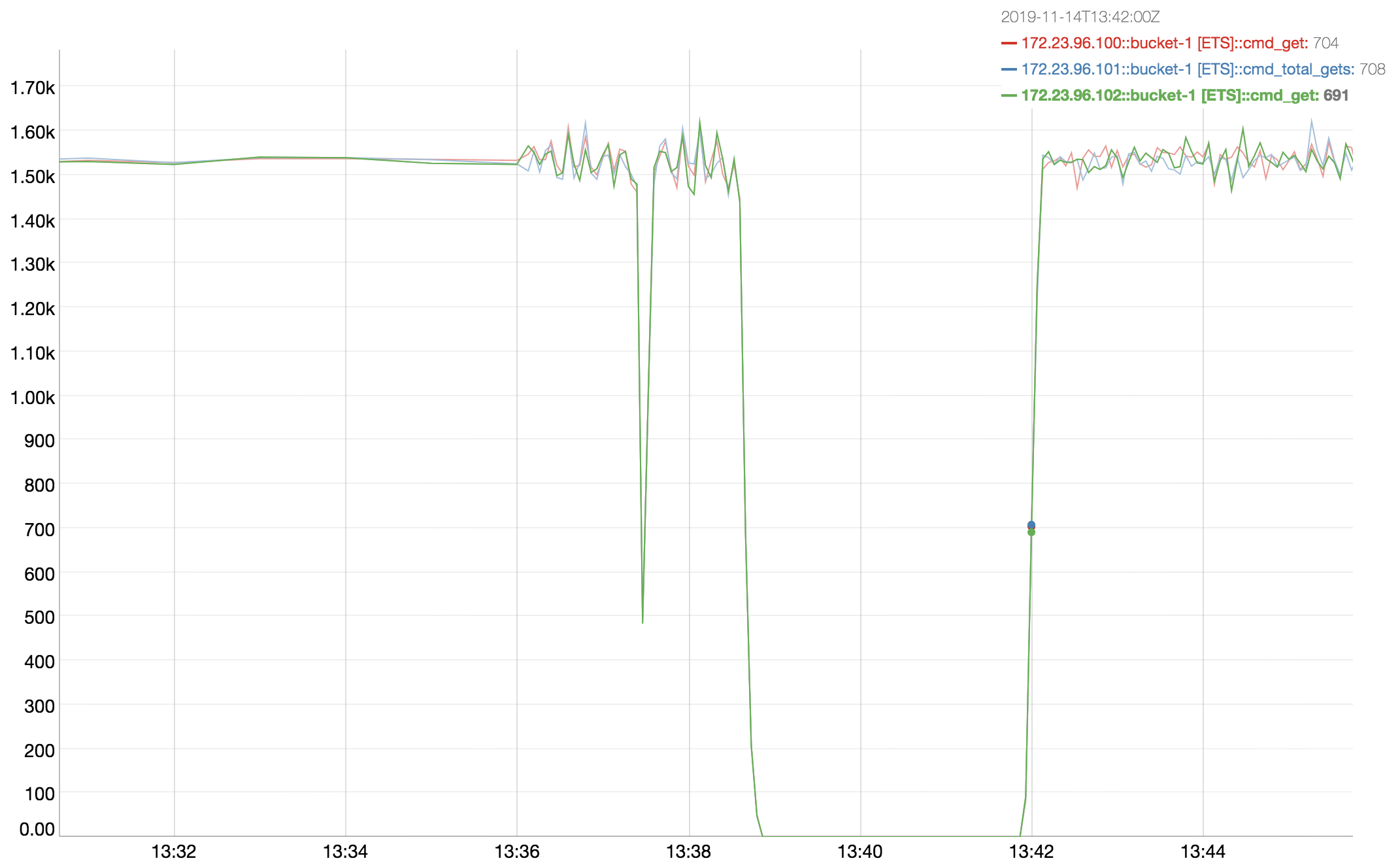
(Note that the mortimer timestamps are in GMT - 8 hours ahead of the timestamps in the logs.)
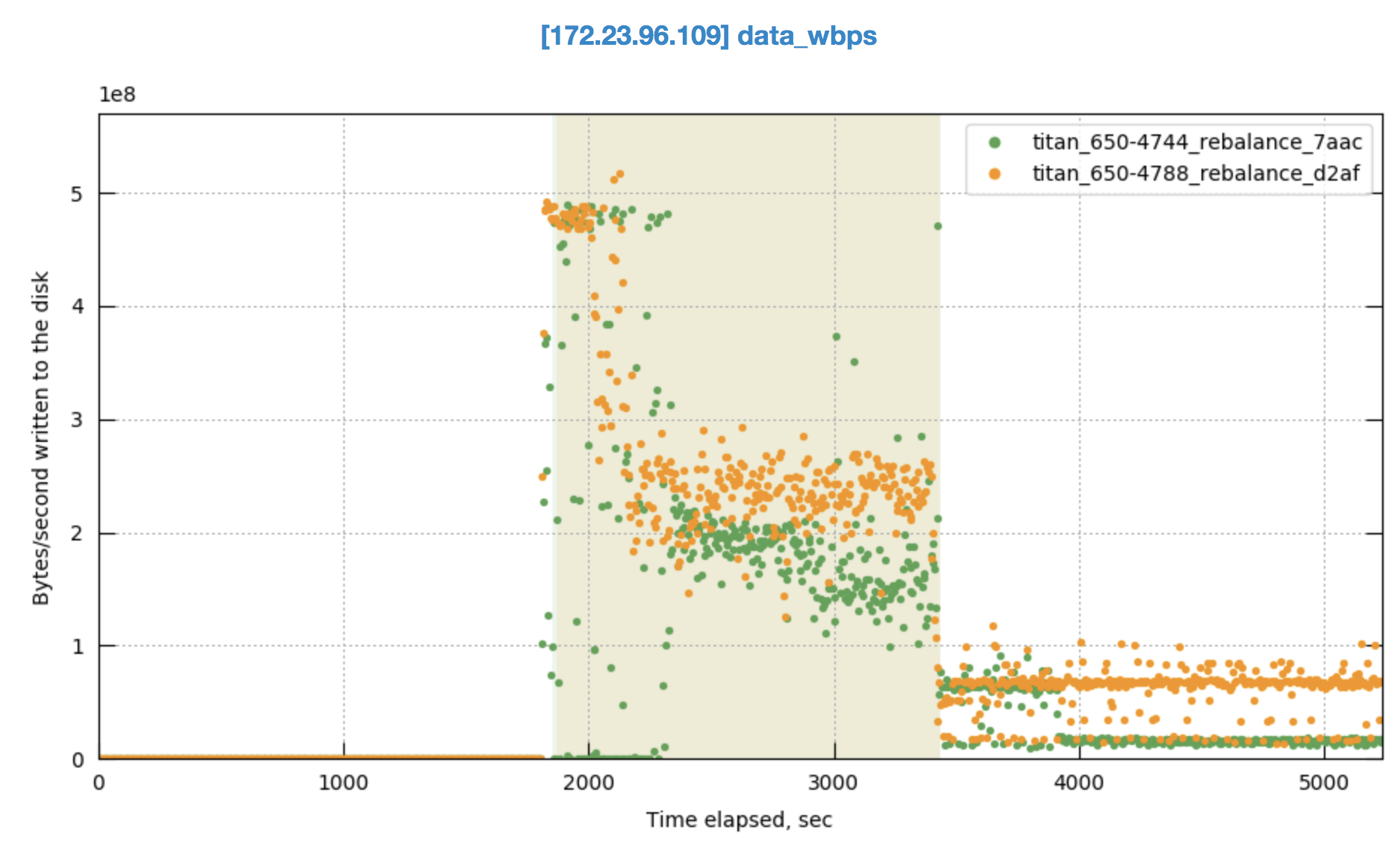
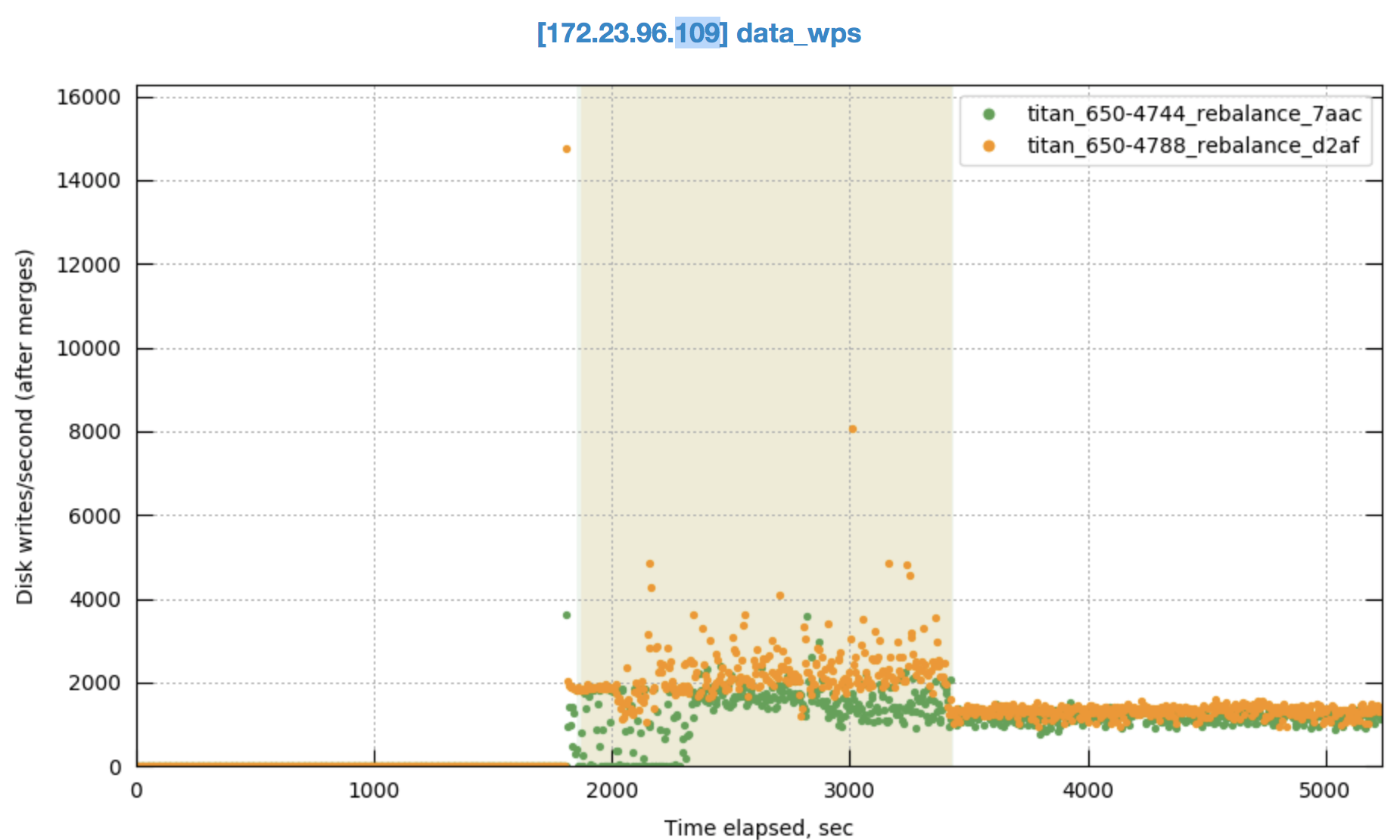
We don't see this in the previous build that was tested 6.5.0-4744: http://cbmonitor.sc.couchbase.com/reports/html/?snapshot=titan_650-4788_rebalance_d2af&label=%226.5.0-4788%209-%3E9%20swap%20rebalance%22&snapshot=titan_650-4744_rebalance_7aac&label=%226.5.0-4744%209-%3E9%20swap%20rebalance%22#19046bfb651c6e0796fef70b7b4a833b.
This occurs during the early part of the rebalance when we're moving a lot of replicas. With the sharding change we're able to move even more replicas.
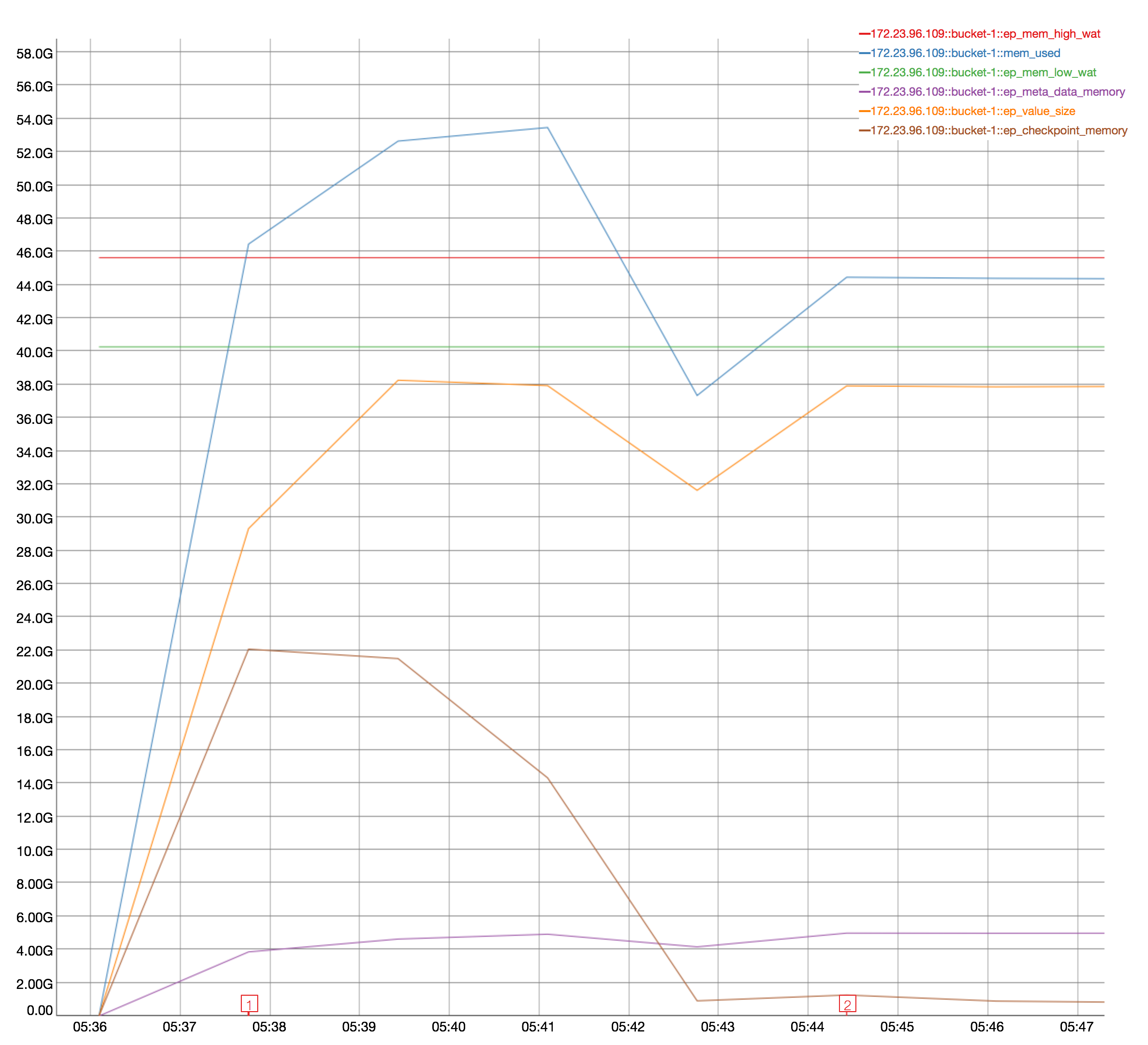
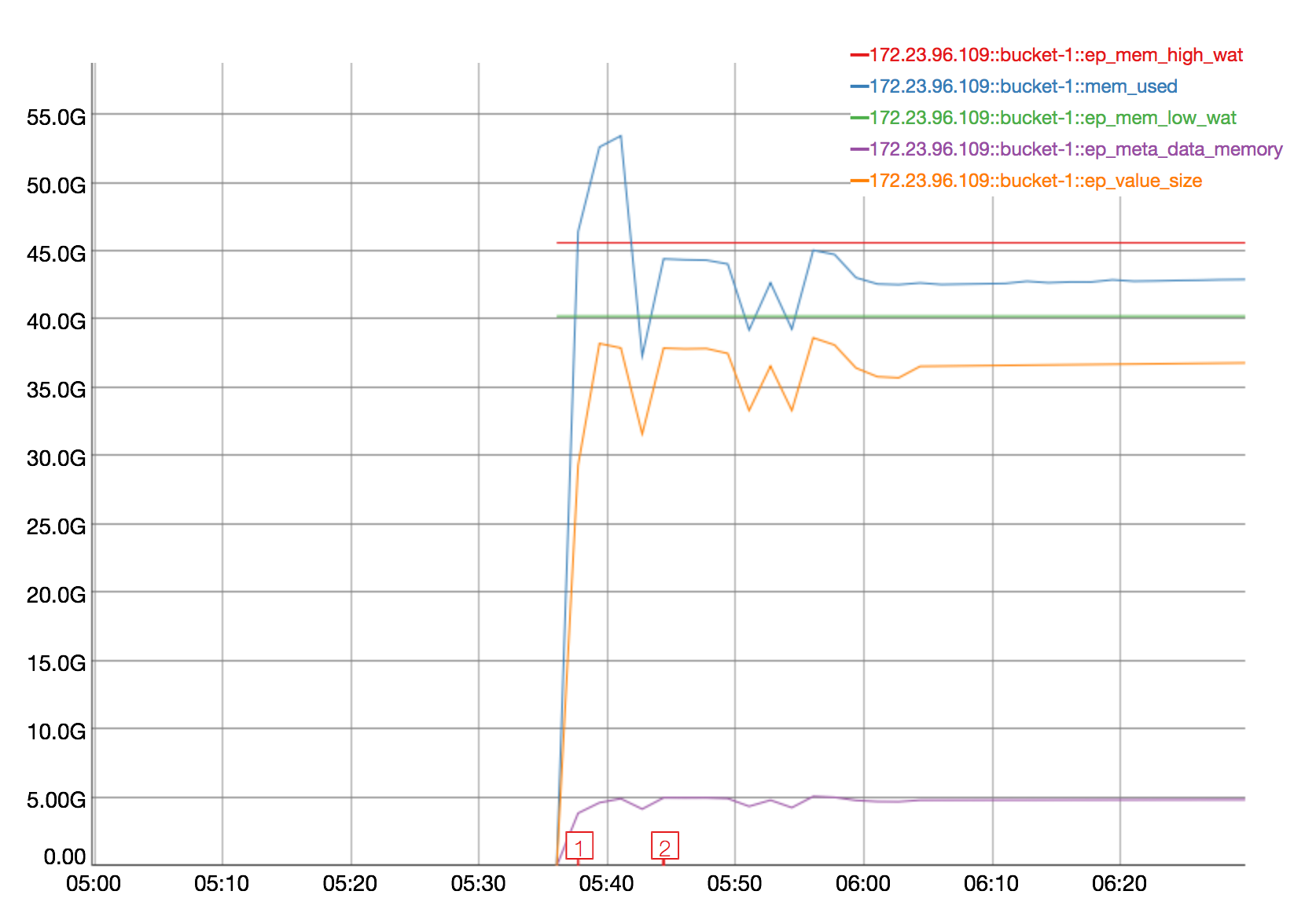
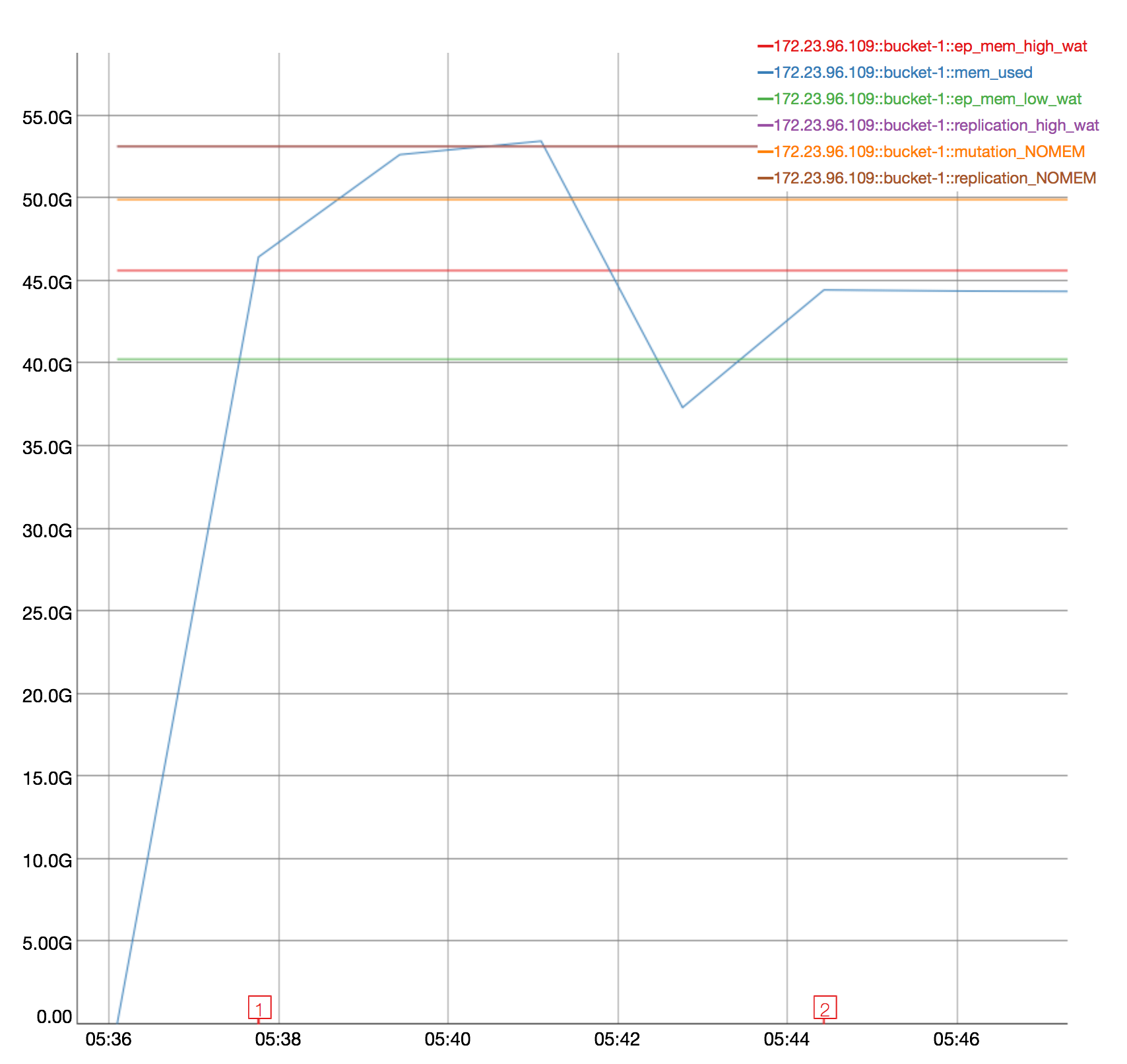
At first I thought it might be CPU, but CPU is only high on node .109 that's getting rebalanced in (where the CPU hits about 50%.) Then I thought the drop might possibly be related to compaction, but I didn't see evidence of compaction during this time.
Then I noticed these messages in the logs approximately during this time:
2019-11-14T05:36:09.885569-08:00 INFO (bucket-1) DCP (Producer) eq_dcpq:replication:ns_1@172.23.96.100->ns_1@172.23.96.109:bucket-1 - Notifying paused connection now that DcpProducer::BufferLog is no longer full; ackedBytes:52429522, bytesSent:0, maxBytes:52428800
|
2019-11-14T05:36:12.816088-08:00 INFO (bucket-1) DCP (Producer) eq_dcpq:replication:ns_1@172.23.96.100->ns_1@172.23.96.109:bucket-1 - Notifying paused connection now that DcpProducer::BufferLog is no longer full; ackedBytes:104858323, bytesSent:0, maxBytes:52428800
|
2019-11-14T05:36:15.658150-08:00 INFO (bucket-1) DCP (Producer) eq_dcpq:replication:ns_1@172.23.96.100->ns_1@172.23.96.109:bucket-1 - Notifying paused connection now that DcpProducer::BufferLog is no longer full; ackedBytes:157287648, bytesSent:0, maxBytes:52428800
|
...
|
Basically every couple of seconds the replication queue between 100 and 109 gets full, then gets unblocked and can continue. These logs occur a minute or two before the ops drop to zero and then cease right around the times the ops start going again.
$ fgrep "Notifying paused connectio" memcached.log | grep -o "2019-11-14T..:..:" | uniq -c
|
54 2019-11-14T05:36:
|
26 2019-11-14T05:37:
|
23 2019-11-14T05:38:
|
79 2019-11-14T05:39:
|
12 2019-11-14T05:40:
|
27 2019-11-14T05:41:
|
11 2019-11-14T05:42:
|
Similar logs at the same time occur on all the nodes. E.g. on node .101:
$ fgrep "Notifying paused connectio" memcached.log | grep -o "2019-11-14T..:..:" |uniq -c
|
56 2019-11-14T05:36:
|
31 2019-11-14T05:37:
|
25 2019-11-14T05:38:
|
79 2019-11-14T05:39:
|
17 2019-11-14T05:40:
|
14 2019-11-14T05:41:
|
However, it turns out that we also see these traces on 4744. It's just that there's a slightly smaller number of them (222 vs 210) and they occur over 8 minutes not 7.
$ fgrep "Notifying paused connectio" memcached.log | grep -o "2019-11-..T..:..:" | uniq -c
|
56 2019-11-04T15:33:
|
21 2019-11-04T15:34:
|
36 2019-11-04T15:35:
|
23 2019-11-04T15:36:
|
18 2019-11-04T15:37:
|
14 2019-11-04T15:38:
|
28 2019-11-04T15:39:
|
14 2019-11-04T15:40:
|
At any rate, the ops shouldn't go to zero.
6.5.0-4744 job: http://perf.jenkins.couchbase.com/job/titan-reb/927/
6.5.0-4788 job: http://perf.jenkins.couchbase.com/job/titan-reb/947/

{kind=link}
{kind=link}